Apa Itu Pengakaran Data dalam AI? Panduan Praktis untuk Keandalan Model LLM

Emma Foster
Machine Learning Engineer
TL;DR
- Pengikatan data menghubungkan hasil AI dengan sumber informasi yang dapat dipercaya, saat ini, dan relevan.
- Pengikatan data mengurangi jawaban yang tidak didukung dengan menambahkan konteks saat inferensi.
- Data pengikatan dapat mencakup dokumen, basis data, hasil pencarian, katalog, kebijakan, dan catatan yang diizinkan.
- RAG adalah teknik umum untuk pengikatan data, tetapi bukan seluruh disiplinnya.
- Pengikatan data yang kuat memerlukan pemeriksaan kualitas, izin, evaluasi pengambilan, kutipan, dan pemantauan.
- Tim yang menggunakan otomatisasi harus mengumpulkan data secara sah dan menangani tantangan CAPTCHA hanya dalam alur kerja yang diizinkan.
Pendahuluan
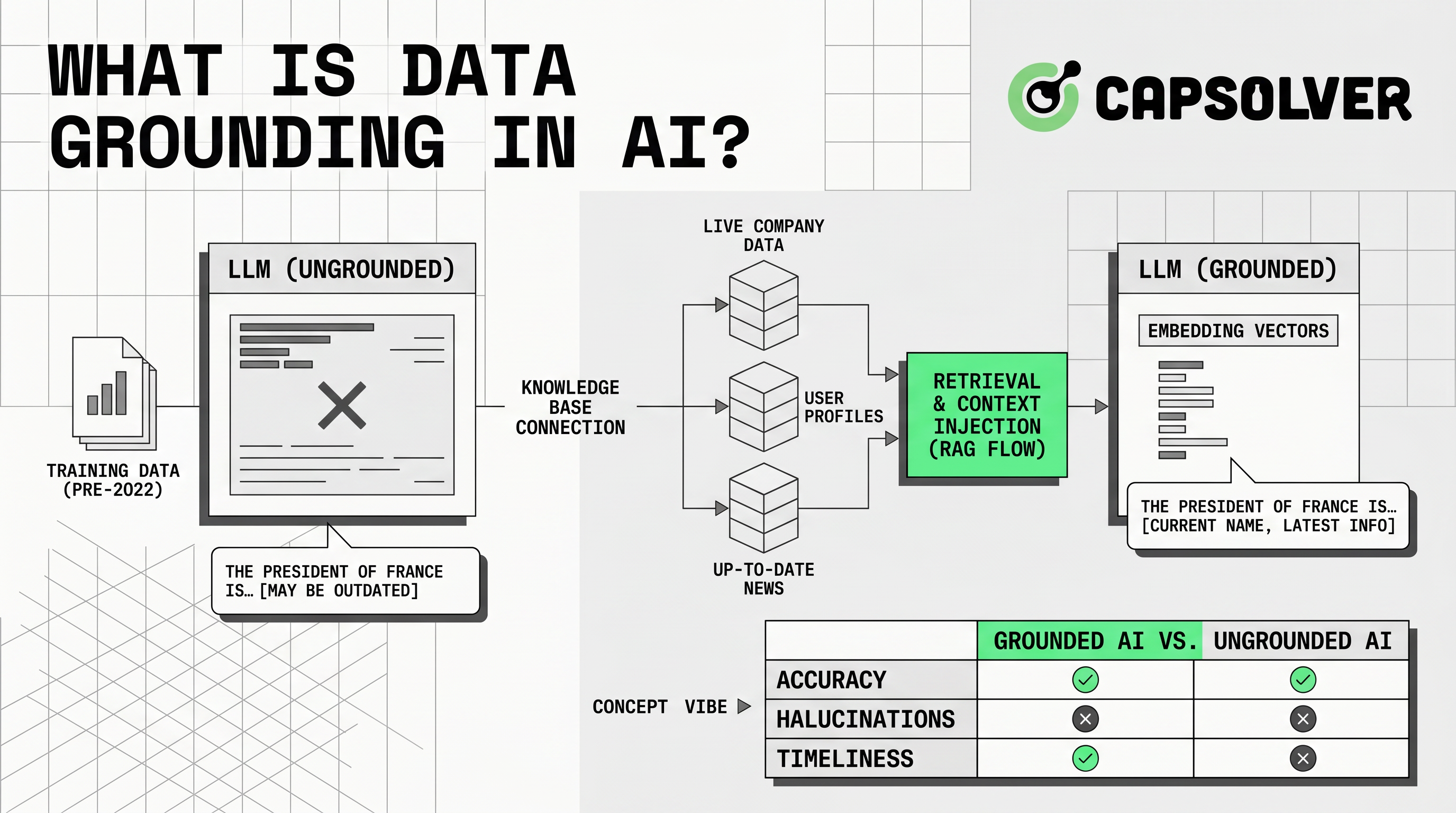
Pengikatan data adalah praktik yang membuat jawaban AI lebih akurat, saat ini, dan dapat diverifikasi. Ini memberikan model konteks yang tepat sebelum menjawab. Panduan ini ditujukan untuk tim produk, tim SEO, pengembang, dan tim otomatisasi yang membangun alat AI di atas LLM. Anda akan belajar apa yang dimaksud dengan pengikatan data dalam AI, bagaimana cara kerjanya, bagaimana berbeda dari RAG dan fine-tuning, serta bagaimana menerapkannya secara bertanggung jawab. Nilainya praktis: sistem AI yang terikat dapat merujuk sumber, menghormati izin, dan mengurangi jawaban yang usang. Ketika alur kerja otomatisasi yang sah bertemu dengan validasi lalu lintas atau tantangan CAPTCHA, CapSolver dapat mendukung proses pengujian yang sesuai.
Definisi Pengikatan Data
Pengikatan data berarti mengikat respons AI dalam konteks eksternal yang dapat dipercaya. Aplikasi menyediakan informasi yang relevan ke model saat pengguna bertanya. Microsoft mendefinisikan data pengikatan sebagai informasi yang diberikan ke model bahasa saat inferensi untuk meningkatkan akurasi dan relevansi melalui pedoman Azure Well-Architected Microsoft.
Pengikatan data penting karena LLM memprediksi bahasa. Mereka tidak secara otomatis tahu harga terbaru, kebijakan, dokumen, catatan pelanggan, atau data pasar publik Anda. Tanpa konteks yang dapat dipercaya, jawaban bisa terdengar percaya diri sementara melewatkan fakta. Dengan pengikatan data, sistem dapat mengambil materi sumber, menyisipkannya ke dalam prompt, dan meminta model menjawab dari materi tersebut.
Pengikatan data AI bukan hanya trik prompt. Ini adalah pola desain data. Termasuk pemilihan sumber, pembersihan, indeks, kontrol akses, pengambilan, generasi respons, kutipan, evaluasi, dan pemantauan.
Mengapa Pengikatan Data Penting untuk Akurasi AI
Pengikatan data meningkatkan keandalan AI dengan mempersempit ruang jawaban model. Google Cloud menggambarkan pengikatan perusahaan sebagai menghubungkan model ke informasi web, data perusahaan, basis data, aplikasi, dan sumber yang dapat dipercaya untuk meningkatkan kelengkapan dan akurasi melalui kebenaran perusahaan Google Cloud.
Ini berguna untuk domain yang berubah cepat. Inventaris, kebijakan dukungan, dokumentasi, harga, dan jadwal acara sering berubah. Model yang dilatih beberapa bulan lalu tidak bisa tahu setiap pembaruan. Pengikatan data memberikan jalur ke informasi terbaru tanpa melatih ulang model setiap hari.
Pengikatan data juga membantu tim menjelaskan jawaban. Kutipan, timestamp, dan bidang sumber mendukung QA, tinjauan kepatuhan, dan kepercayaan pengguna.
Cara Kerja Pengikatan Data
Pengikatan data bekerja melalui alur pengambilan dan generasi. Sistem terlebih dahulu mengidentifikasi sumber yang dapat dipercaya. Kemudian, mempersiapkan sumber tersebut untuk pencarian. Sumber umum termasuk pusat bantuan, manual, API, basis data SQL, indeks vektor, aliran produk, dan halaman publik yang disetujui.
Langkah berikutnya adalah pengolahan. Tim membersihkan dokumen, menghapus duplikat, menyamakan metadata, membagi konten menjadi bagian, dan menyimpannya dalam indeks pencarian. Indeks mungkin menggunakan pencarian kata kunci, pencarian vektor, pencarian hibrid, atau pencarian grafik. Microsoft menyarankan mengeksternalisasi data pengikatan ke indeks pencarian ketika meningkatkan pengambilan, kinerja, dan perlindungan sistem sumber melalui desain data pengikatan AI.
Ketika pengguna bertanya, sistem mengambil catatan yang relevan. Ini menyaring berdasarkan izin, kekinian, bahasa, wilayah, atau garis produk. Kemudian menambahkan konteks yang diambil ke prompt model. Model menjawab dari konteks tersebut dan mungkin mengembalikan kutipan sumber.
Pengikatan data berhasil ketika pengambilan akurat. Sistem yang kuat mengukur relevansi, kejujuran, latensi, dan cakupan sumber.
Ringkasan Perbandingan
Pengikatan data tumpang tindih dengan beberapa metode AI. Tabel di bawah menunjukkan perbedaan praktis.
| Metode | Tujuan Utama | Kasus Penggunaan Terbaik | Keterbatasan Utama |
|---|---|---|---|
| Pengikatan data | Mengikat jawaban dalam konteks yang dapat dipercaya | Jawaban yang saat ini dan didukung sumber | Memerlukan pengambilan dan tata kelola yang kuat |
| RAG | Mengambil dokumen sebelum generasi | Q&A basis pengetahuan dan agen dukungan | Bisa mengambil konteks yang tidak relevan atau usang |
| Fine-tuning | Mengubah perilaku model melalui contoh | Perilaku gaya, format, atau domain | Tidak ideal untuk fakta yang berubah |
| Engineering prompt | Mengarahkan perilaku dengan instruksi | Tugas kecil dan format respons | Tidak bisa menyediakan fakta yang hilang sendirian |
| Guardrails | Memaksakan kebijakan dan kontrol output | Pemeriksaan keamanan, format, dan kepatuhan | Tidak bisa menggantikan konteks sumber yang diverifikasi |
Perbandingan ini menunjukkan mengapa pengikatan data lebih luas dari RAG. RAG adalah pola implementasi umum. Pengikatan data adalah disiplin penuh menghubungkan output model ke bukti yang dapat dipercaya.
Sumber Pengikatan Data Umum
Pengikatan data dimulai dengan kualitas sumber. Tim harus mengurutkan sumber berdasarkan otoritas, kekinian, kepemilikan, dan tingkat izin.
Sumber internal sering memberikan nilai bisnis terbesar. Ini termasuk catatan CRM, tiket, kebijakan, sistem inventaris, spesifikasi produk, dan basis pengetahuan. Mereka memerlukan kontrol akses yang ketat.
Sumber eksternal menambahkan kekinian dan cakupan. Ini termasuk dokumentasi resmi, panduan pemerintah, dataset publik, badan standar, dan data pasar yang dapat dipercaya. NIST menyatakan bahwa Kerangka Manajemen Risiko AI-nya membantu organisasi mengelola risiko terhadap individu, organisasi, dan masyarakat melalui NIST AI RMF. Sumber ini berguna ketika menulis kebijakan untuk sistem AI yang dapat dipercaya.
Data web publik dapat mendukung pemantauan pasar, penelitian SEO, dan analisis kompetitif. Tim harus menjaga hal ini sah dan wajar. Mereka harus menghormati ketentuan situs, batas permintaan, panduan robots yang berlaku, dan kewajiban privasi. Sumber CapSolver tentang AI dan otomatisasi dan alur kerja otomatisasi adalah titik awal yang berguna untuk proses yang bertanggung jawab.
Alur Kerja Produksi untuk Pengikatan Data
Pengikatan data bekerja paling baik dengan model operasional yang jelas. Pertama, tentukan batas jawaban. Putuskan apa yang AI dapat jawab, sumber mana yang dapat digunakan, dan kapan harus menolak atau meningkatkan.
Kedua, persiapkan data. Hapus duplikat, catatan yang usang, bidang pribadi, dan boilerplate yang bising. Tambahkan metadata seperti pemilik, tanggal, wilayah, produk, bahasa, dan tingkat izin. Ini membuat pengambilan lebih akurat.
Ketiga, desain pengambilan. Gunakan pencarian kata kunci untuk istilah tepat, pencarian vektor untuk kesamaan semantik, dan filter untuk catatan yang diizinkan.
Keempat, evaluasi kinerja. Buat kumpulan uji pertanyaan nyata. Skor relevansi pengambilan, kejujuran jawaban, akurasi kutipan, dan latensi. Tinjau kasus tepi dengan ahli domain. Jangan hanya mengandalkan kepercayaan model.
Kelima, pantau drift. Pengikatan data bisa gagal ketika dokumen menjadi usang, indeks rusak, izin berubah, atau tujuan pengguna berubah. Sistem kritis memerlukan pemeriksaan kekinian otomatis dan jalur tinjauan manusia.
Pertimbangan Kepatuhan dan Keamanan
Pengikatan data harus menghormati batas hukum, privasi, dan keamanan. Akses teknis tidak berarti izin. Sistem AI yang terikat harus menghindari data pribadi, terbatas, sensitif, atau tidak sah kecuali organisasi memiliki dasar hukum jelas dan izin pengguna.
Risiko keamanan juga penting. OWASP menyebutkan injeksi prompt, pengungkapan informasi sensitif, agensi berlebihan, dan ketergantungan berlebihan sebagai risiko utama untuk aplikasi LLM melalui OWASP Top 10 untuk Aplikasi LLM. Pengikatan data dapat mengurangi klaim yang tidak didukung, tetapi dapat memperkenalkan risiko jika pengambilan menerima konten jahat atau mengungkap catatan yang dilindungi.
Tim harus menggunakan pengambilan yang sadar izin. Mereka harus menyucikan teks yang tidak tepercaya, mencatat ID sumber alih-alih catatan sensitif, dan memisahkan data berdasarkan klasifikasi.
Tim otomatisasi memerlukan perhatian ekstra. Pengumpulan data web harus fokus pada data publik yang diizinkan, laju permintaan yang wajar, dan tujuan bisnis yang terdokumentasi. Ketika tantangan CAPTCHA muncul dalam QA, pemantauan, atau alur kerja data yang diizinkan, tim harus memperlakukannya sebagai bagian dari validasi lalu lintas. Artikel CapSolver tentang pengumpulan data web publik dan panduannya tentang tantangan CAPTCHA dapat membantu tim memahami konteks operasional.
Di Mana CapSolver Cocok dalam Alur Kerja AI yang Bertanggung Jawab
CapSolver relevan ketika pengikatan data bergantung pada alur kerja otomatisasi yang sah. Beberapa tim mengumpulkan data publik untuk pemantauan harga, pemeriksaan SEO, verifikasi iklan, pengujian QA, atau penelitian. Alur kerja ini mungkin menghadapi tantangan CAPTCHA selama penjelajahan atau pengujian normal.
CapSolver dapat membantu tim menangani tantangan tersebut melalui layanan yang dirancang untuk lingkungan otomatisasi. Rekomendasi ini sempit dan berfokus pada kepatuhan. Gunakan hanya di mana Anda memiliki izin, menghormati aturan yang berlaku, dan menghindari data yang terbatas atau sensitif. Tim dapat meninjau produk CapSolver untuk memahami skenario yang didukung dan sesuaikan dengan alur kerja yang disetujui.
Klaim Kode Bonus CapSolver Anda
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap penyetoran — tanpa batas.
Klaim sekarang di Dasbor CapSolver Anda
Pengikatan data dan penanganan CAPTCHA tidak boleh dicampur secara sembarangan. Lapisan pengikatan menentukan bukti yang dapat digunakan AI. Lapisan otomatisasi mengumpulkan atau memeriksa data di bawah aturan yang disetujui. Memisahkan lapisan ini membuat audit lebih mudah dan mengurangi risiko operasional.
Metrik Praktis untuk Sistem AI yang Terikat
Pengikatan data membutuhkan standar kualitas yang dapat diukur. Relevansi pengambilan bertanya apakah konteks yang dikembalikan menjawab pertanyaan. Skor rendah berarti model bekerja dengan bukti yang lemah.
Kejujuran jawaban bertanya apakah jawaban tetap dalam sumber yang diambil. Ini penting karena jawaban yang lancar masih bisa menambahkan detail yang tidak didukung.
Akurasi kutipan memeriksa apakah setiap sumber yang dikutip mendukung kalimat yang diikuti. Kekinian melacak usia dokumen, waktu pembaruan indeks, dan frekuensi pembaruan sumber. Kualitas penolakan memeriksa apakah sistem mengatakan ketika bukti hilang.
Kesimpulan dan CTA
Pengikatan data adalah salah satu cara paling praktis untuk membuat sistem AI lebih andal. Ini menghubungkan jawaban dengan konteks yang dapat dipercaya, meningkatkan kekinian, mendukung kutipan, dan membantu tim mengelola risiko. RAG sering menjadi bagian dari solusi, tetapi pengikatan data tingkat produksi juga memerlukan data bersih, izin kuat, evaluasi, pemantauan, dan praktik otomatisasi yang bertanggung jawab.
Jika alur kerja AI Anda bergantung pada pemantauan data publik, otomatisasi browser, pengujian QA, atau penelitian, rencanakan pipa data dengan hati-hati. Pertahankan akses sumber secara sah. Pertahankan data sensitif dilindungi. Tinjau output sebelum menggunakan mereka untuk keputusan penting. Untuk alur kerja yang disetujui yang menghadapi tantangan CAPTCHA, pertimbangkan mengevaluasi CapSolver sebagai bagian dari tumpukan otomatisasi yang sesuai.
FAQ
Apa itu pengikatan data dalam AI?
Pengikatan data adalah proses menghubungkan jawaban AI dengan konteks yang dapat dipercaya. Konteks mungkin berasal dari dokumen, basis data, API, indeks pencarian, atau sumber publik yang disetujui. Ini membantu model menjawab dari bukti alih-alih hanya mengandalkan data pelatihan.
Apakah pengikatan data sama dengan RAG?
Tidak. RAG adalah cara umum untuk menerapkan pengikatan data. Pengikatan data lebih luas. Ini mencakup tata kelola sumber, indeks, izin, evaluasi pengambilan, kutipan, pemantauan, dan aturan eskalasi.
Mengapa pengikatan data mengurangi jawaban AI yang tidak didukung?
Pengikatan data mengurangi jawaban yang tidak didukung karena memberikan bukti relevan ke model saat inferensi. Model dapat menjawab dari konteks saat ini alih-alih mengisi celah dari pola statistik saja.
Data apa yang harus digunakan untuk pengikatan data untuk LLM?
Gunakan data yang akurat, diizinkan, saat ini, dan relevan. Contoh yang baik termasuk dokumentasi resmi, catatan produk, kebijakan dukungan, basis pengetahuan, dataset publik, dan basis data bisnis yang disetujui. Hindari data pribadi atau terbatas tanpa izin yang tepat.
Bagaimana tim harus menerapkan pengikatan data secara bertanggung jawab?
Tim harus menentukan aturan sumber, menerapkan kontrol akses, memantau kualitas pengambilan, dan meninjau output yang berdampak besar. Tim otomatisasi harus mengumpulkan data secara sah, menghormati aturan situs, dan menggunakan layanan terkait CAPTCHA hanya dalam alur kerja yang diizinkan.
Lihat Lebih Banyak
Web ScrapingJul 22, 2026
Pemantauan Regresi SEO Teknis: Pipeline Otomasi
Bangun pemantauan regresi SEO teknis dengan baseline yang diberi versi, perbedaan semantik, notifikasi yang diverifikasi, dan langkah pemulihan CAPTCHA opsional yang diotorisasi.
CloudflareJul 22, 2026
Pemecah CAPTCHA MCP: Panduan Integrasi Cloudflare Turnstile
Bangun alur kerja MCP Cloudflare Turnstile yang berdasarkan kebijakan dengan CapSolver, pengulangan terbatas, log yang telah dihapus bagian tertentu, pemeriksaan sesi, dan validasi hasil.