Keamanan Pengambilan Data Web: Praktik Terbaik untuk Melindungi Data & Menghindari Deteksi

Emma Foster
Machine Learning Engineer

TL;Dr:
- Kepatuhan Hukum & Etika: Patuhi
robots.txtdan ketentuan layanan untuk pengumpulan data yang etis. - Meniru Perilaku Manusia: Terapkan jeda, rotasi User-Agent, dan manajemen cookie untuk menghindari deteksi bot.
- Gunakan Proxy: Gunakan berbagai jenis proxy (residential, datacenter) untuk mendistribusikan permintaan dan menyembunyikan IP Anda.
- Menangani CAPTCHA: Integrasikan layanan penyelesaian CAPTCHA otomatis untuk pengumpulan data yang tidak terganggu.
- Pantau & Sesuaikan: Pantau kinerja pengambilan data dan perubahan situs web secara terus-menerus untuk mempertahankan efektivitasnya.
Pendahuluan
Web scraping, teknik pengambilan data yang kuat, menawarkan tantangan keamanan yang signifikan dan risiko deteksi. Panduan ini menjelaskan praktik terbaik keamanan web scraping, membantu profesional data melindungi data mereka dan menghadapi sistem anti-bot. Memahami mekanisme deteksi dan menerapkan strategi yang kuat memastikan pengumpulan data yang efisien, etis, dan tidak terganggu. Kami menjelaskan konsep-konsepnya, membangun pengetahuan dasar, dan menawarkan solusi praktis untuk meningkatkan operasi web scraping Anda. Untuk penjelasan lebih dalam tentang dasar-dasar, eksplorasi apa itu web scraping.
Memahami Keamanan Web Scraping: Apa, Mengapa, dan Bagaimana
Web scraping yang aman dan efektif memerlukan pemahaman tentang cara situs web melindungi informasi mereka. Keamanan web scraping melibatkan metode dan praktik untuk mencegah scraper dari deteksi, pemblokiran, atau masalah hukum. Tujuannya adalah mengumpulkan data sambil menghormati kebijakan situs web dan menghindari pemicu sistem anti-bot. Ini menyeimbangkan efisiensi dengan kecil hati, membuat aktivitas web scraping terlihat sebagai interaksi pengguna yang sah.
Essensi Deteksi Web Scraping
Situs web menggunakan berbagai teknik untuk mengidentifikasi dan mencegah pengambilan data otomatis. Mekanisme deteksi menganalisis pola yang menyimpang dari perilaku manusia biasa. Tingkat permintaan yang tinggi dari satu IP atau header browser yang hilang dapat segera menandai sebuah scraper. Memahami pemicu ini penting untuk strategi pengambilan data yang tangguh. Teknologi anti-bot terus berkembang, memerlukan penyesuaian terus-menerus pada praktik keamanan web scraping.
Cara Kerja Sistem Anti-Bot
Sistem anti-bot menganalisis berbagai poin data dari permintaan yang masuk, membangun profil pengunjung dan mencari anomali. Indikator utama termasuk reputasi IP, fingerprint browser, header permintaan, dan pola perilaku. Perbedaan signifikan dari profil manusia dapat memicu respons dari tantangan CAPTCHA hingga pemblokiran IP. Keamanan web scraping yang efektif bertujuan untuk bercampur dengan lalu lintas sah, membuat sistem sulit membedakannya.
Pengetahuan Terstruktur: Definisi, Klasifikasi, dan Skenario
Membangun fondasi yang kuat dalam keamanan web scraping memerlukan klasifikasi komponen dan memahami peran mereka. Pendekatan terstruktur ini membantu mengidentifikasi langkah pencegahan yang tepat untuk berbagai tantangan pengambilan data.
Konsep Kunci dalam Keamanan Web Scraping
- Rotasi IP: Mengganti alamat IP untuk permintaan agar menghindari batas permintaan dan pemblokiran IP, membuat permintaan terlihat dari pengguna yang berbeda. Teknik ini penting untuk mendistribusikan beban permintaan dan mencegah satu IP dari ditandai.
- Manajemen User-Agent: Menetapkan header
User-Agentyang sesuai untuk meniru browser web populer, karena sistem anti-bot memeriksa ini untuk keabsahan. Secara berkala mengganti User-Agent dapat meningkatkan kecil hati lebih lanjut. - Pembatasan Permintaan: Menambahkan jeda antara permintaan untuk meniru pola penjelajahan manusia dan mencegah beban server. Mengacak jeda ini membuat aktivitas pengambilan data terlihat lebih alami.
- Fingerprint Browser: Mengumpulkan karakteristik browser unik (misalnya, plugin, font, resolusi layar) untuk mengidentifikasi dan melacak pengguna. Sistem anti-bot canggih menggunakan ini untuk mendeteksi browser tanpa head. Scraper harus bertujuan untuk menampilkan fingerprint browser yang konsisten dan umum.
- CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart): Uji coba tantangan-respons untuk memverifikasi pengguna manusia. Berbagai jenis tersedia dengan logika pengenalan yang berbeda, menjadi penghalang signifikan bagi sistem otomatis.
Klasifikasi Pengukuran Anti-Bot
Situs web menerapkan pertahanan bertingkat terhadap scraper:
- Pembatasan Tingkat: Membatasi permintaan dari satu IP dalam jangka waktu tertentu. Melebihi batas sering mengakibatkan pemblokiran sementara atau permanen.
- Pemblokiran IP: Memblokir alamat IP atau rentang yang diketahui berbahaya berdasarkan data historis atau intelijen ancaman. Inilah sebabnya penggunaan proxy yang beragam sangat penting.
- Tantangan CAPTCHA: Menampilkan teka-teki visual atau interaktif untuk memverifikasi interaksi manusia (misalnya, reCAPTCHA, Cloudflare Turnstile). Ini dirancang agar sulit dipecahkan oleh bot.
- Pemeriksaan User-Agent dan Header: Memvalidasi string
User-Agentdan header HTTP lainnya untuk menyerupai browser sah. Header yang tidak konsisten atau usang dapat segera menandai sebuah bot. - Honeypots: Tautan atau elemen tersembunyi yang dirancang untuk menangkap bot otomatis. Mengikuti tautan ini menandai scraper sebagai non-manusia, menyebabkan pemblokiran instan.
- Tantangan JavaScript: Membutuhkan eksekusi JavaScript untuk menampilkan konten atau menyelesaikan teka-teki komputasi, mencegah scraper HTTP sederhana yang tidak mengeksekusi JavaScript.
- Fingerprint Browser: Menganalisis karakteristik browser yang halus untuk mengidentifikasi alat otomatis. Termasuk memeriksa ketidakkonsistenan dalam properti browser yang mungkin menunjukkan browser tanpa head.
Skenario Penggunaan untuk Pengambilan Data yang Aman
Pengambilan data yang aman penting untuk berbagai aplikasi, termasuk riset pasar, agregasi konten, dan intelijen kompetitif. Misalnya, bisnis e-commerce yang mengambil harga kompetitor membutuhkan profil rendah untuk menghindari pemblokiran dan mengumpulkan data akurat dan real-time. Peneliti akademik yang mengumpulkan data publik harus memastikan metode yang sesuai untuk menghindari masalah hukum dan etika. Prinsip keamanan web scraping berlaku universal, menekankan kebutuhan strategi yang kuat untuk memastikan integritas data dan kelangsungan operasional.
Latar Belakang Teknis: Jenis CAPTCHA, Logika Pengenalan, dan Kontrol Risiko
CAPTCHA adalah penghalang signifikan, dirancang untuk membedakan pengguna manusia dari bot. Memahami dasar teknisnya penting untuk mengatasi mereka. Teknologi CAPTCHA terus berkembang untuk mengatasi penyelesaian otomatis.
Jenis CAPTCHA Umum dan Logikanya
- reCAPTCHA (Google): Berkembang dari pengenalan teks sederhana (v1) menjadi analisis perilaku dan skor risiko yang canggih (v2 "Saya bukan robot" checkbox, reCAPTCHA yang tidak terlihat) dan analisis latar belakang yang tidak terlihat (v3). Logika v2 dan v3 bergantung berat pada pola interaksi pengguna, fingerprint browser, dan reputasi IP. Riwayat penjelajahan yang bersih, gerakan mouse biasa, dan perilaku pengguna yang konsisten mengurangi kemungkinan ditantang.
- Cloudflare Turnstile: Alternatif reCAPTCHA yang fokus pada privasi, sering menggunakan tantangan berbasis gambar atau verifikasi pasif. Logikanya berfokus pada akurasi dan konsistensi pilihan pengguna atau sinyal perilaku tanpa memerlukan interaksi pengguna eksplisit dalam banyak kasus.
- CAPTCHA Berbasis Gambar: Ini memerlukan mengidentifikasi objek, karakter, atau pola dalam kumpulan gambar. Logika pengenalan menggunakan pemadanan pola visual, yang sulit bagi bot tanpa kemampuan visi komputer canggih.
- CAPTCHA Audio: Ini menampilkan klip audio yang distorsi dari angka atau huruf untuk ditranskripsikan. Bot biasanya kesulitan dengan distorsi, suara latar, dan aksen yang berbeda, membuatnya efektif terhadap solvers otomatis sederhana.
Logika Pengenalan dan Kontrol Risiko
Sistem anti-bot, termasuk yang menerapkan CAPTCHA, menggunakan mekanisme kontrol risiko yang canggih. Mereka menganalisis berbagai faktor secara real-time untuk mengevaluasi kemungkinan permintaan berasal dari bot:
- Analisis Perilaku: Ini melibatkan pemeriksaan gerakan mouse, input keyboard, pola scroll, dan waktu yang dihabiskan di halaman. Tindakan yang tidak konsisten atau terlalu presisi, atau tindakan yang terlalu cepat atau terlalu lambat, dapat menandai bot.
- Karakteristik Jaringan: Faktor seperti reputasi IP, negara asal, dan penggunaan VPN atau proxy yang dikenal dievaluasi. IP yang terkait dengan aktivitas berbahaya atau pusat data sering ditandai lebih mudah.
- Lingkungan Browser: Ketidakkonsistenan dalam string
User-Agent, plugin yang hilang, lingkungan eksekusi JavaScript yang tidak biasa, atau ketidakkonsistenan dalam resolusi layar yang dilaporkan dapat menunjukkan browser tanpa head atau skrip otomatis. - Frekuensi dan Volume Permintaan: Permintaan yang sangat tinggi dari sumber tunggal dalam waktu singkat, jauh melebihi pola penjelajahan manusia biasa, adalah indikator kuat aktivitas otomatis.
Faktor risiko yang terakumulasi meningkatkan respons, menyebabkan tantangan CAPTCHA yang lebih ketat, pembatasan tingkat, atau pemblokiran IP secara langsung. Strategi keamanan web scraping bertujuan meminimalkan faktor-faktor ini, membuat scraper terlihat sebagai pengguna manusia sah.
Alur Proses Sederhana untuk Web Scraping yang Aman
Pemahaman tingkat tinggi tentang proses web scraping yang aman bermanfaat untuk menerapkan langkah pencegahan yang efektif.
-
Pengaturan Awal & Konfigurasi:
- Pilih penyedia proxy yang andal: Pilih layanan yang menawarkan jenis IP yang beragam (residential, mobile) dan rotasi. Ini adalah dasar keamanan web scraping, karena membantu mendistribusikan permintaan dan menyembunyikan alamat IP asli Anda.
- Konfigurasi rotasi
User-Agent: Pertahankan stringUser-Agentyang terkini dan ganti mereka per permintaan atau sesi. Ini meniru lingkungan pengguna yang beragam dan menghindari deteksi berdasarkanUser-Agentstatis. - Terapkan jeda permintaan: Tambahkan jeda acak antara permintaan (misalnya, 2-10 detik) untuk meniru kecepatan penjelajahan manusia. Hindari jeda yang terprediksi, seperti jeda tetap yang mudah dideteksi.
-
Pemeriksaan Sebelum Pengambilan Data:
- Periksa
robots.txt: Selalu periksa filerobots.txtsitus target (https://example.com/robots.txt) untuk kebijakan pengambilan data. Mematuhi panduan ini penting untuk kepatuhan hukum dan etika. Mengabaikanrobots.txtdapat menyebabkan masalah hukum dan pemblokiran IP. Ini adalah aspek dasar dari keamanan web scraping yang bertanggung jawab. - Analisis struktur situs web: Pahami struktur HTML dan identifikasi honeypots (misalnya, elemen
display: noneatauvisibility: hidden) untuk menghindari berinteraksi dengan mereka. Berinteraksi dengan honeypots adalah tanda jelas aktivitas otomatis.
- Periksa
-
Eksekusi & Pantau:
- Ambil data: Jalankan skrip Anda, mematuhi jeda dan rotasi proxy yang dikonfigurasi.
- Pantau pemblokiran: Pantau terus-menerus tingkat keberhasilan permintaan dan kode status HTTP. Jika pemblokiran terjadi (misalnya, HTTP 403, 429, atau halaman CAPTCHA), analisis respons untuk mengidentifikasi penyebabnya. Untuk strategi tentang cara menghindari pemblokiran IP, merujuk pada panduan kami yang rinci.
- Sesuaikan dan tingkatkan: Sesuaikan parameter pengambilan data (misalnya, tingkatkan jeda, ubah jenis proxy, perbarui string
User-Agent) berdasarkan pemantauan real-time dan umpan balik dari respons situs web.
-
Setelah Pengambilan Data & Pengelolaan Data:
- Validasi data: Pastikan data yang diambil akurat, lengkap, dan konsisten. Implementasikan pemeriksaan untuk memastikan data bersih dan dapat digunakan.
- Penyimpanan dan keamanan: Simpan data yang dikumpulkan secara aman, mematuhi regulasi perlindungan data seperti GDPR dan CCPA. Pastikan data dienkripsi dan akses dibatasi hanya untuk personel yang berwenang.
Solusi untuk Keamanan Web Scraping yang Lebih Baik
Seiring berkembangnya teknologi anti-bot, strategi pengambilan data yang aman harus terus diperbarui. Solusi ini mengatasi tantangan umum dan memberikan jalur untuk pengumpulan data yang tangguh.
Meniru Perilaku Manusia
Membuat scraper Anda berperilaku seperti pengguna manusia sangat efektif dalam menghindari deteksi:
- Jeda yang Diacak: Gunakan interval acak (misalnya, 5-15 detik) antara permintaan untuk tampil lebih alami, meningkatkan keamanan web scraping. Ini menghindari pola yang terprediksi yang sering ditunjukkan bot.
- Pola Klik yang Realistis: Untuk browser tanpa head, simulasi gerakan mouse dan klik yang alami dengan koordinat dan waktu yang bervariasi. Hindari klik langsung pada elemen tanpa gerakan mouse sebelumnya.
- Manajemen Cookie: Pertahankan dan kelola cookie di antara sesi untuk mempertahankan status dan mengurangi kecurigaan. Situs web sering menggunakan cookie untuk melacak sesi pengguna dan mengidentifikasi pengunjung kembali.
- Header Referer: Tetapkan header
Refereryang sesuai untuk terlihat dari sumber sah (misalnya, mesin pencari atau halaman sebelumnya di situs yang sama), menambah keabsahan permintaan dan keamanan web scraping.
Strategi Proxy Lanjutan
Proxy sangat penting untuk keamanan web scraping. Kombinasi jenis proxy meningkatkan keberhasilan dengan mendistribusikan permintaan dan menyembunyikan alamat IP Anda:
- Proxy Residential: IP yang diberikan oleh Penyedia Layanan Internet (ISP) kepada pengguna rumah tangga. Mereka sangat efektif karena terlihat sebagai lalu lintas pengguna sah, membuatnya sulit bagi sistem anti-bot untuk membedakannya dari pengguna nyata. Proxy residential penting untuk keamanan web scraping yang kuat, terutama untuk target yang sangat dilindungi.
- Proxy Mobile: IP dari penyedia layanan seluler lebih sulit dideteksi karena sifat dinamisnya dan kaitannya dengan perangkat seluler nyata. Mereka menawarkan anonimitas yang lebih tinggi dan sangat baik untuk target dengan pengukuran anti-bot yang ketat.
- Proxy Datacenter: Ini lebih cepat dan murah tetapi lebih mudah dideteksi karena berasal dari pusat data komersial. Mereka cocok untuk situs yang kurang dilindungi atau fase pengujian awal di mana anonimitas bukan prioritas utama.
Ringkasan Perbandingan: Jenis Proxy untuk Keamanan Web Scraping
| Fitur | Proxy Datacenter | Proxy Residential | Proxy Mobile |
|---|---|---|---|
| Tingkat Anonimitas | Rendah hingga Menengah | Tinggi | Sangat Tinggi |
| Risiko Deteksi | Tinggi | Rendah | Sangat Rendah |
| Kecepatan | Tinggi | Menengah | Menengah |
| Biaya | Rendah | Menengah hingga Tinggi | Tinggi |
| Kasus Penggunaan | Situs yang kurang dilindungi | Situs yang sedang dilindungi | Situs yang sangat dilindungi |
| Sumber IP | Pusat data komersial | ISP | Penyedia seluler |
Mengatasi Tantangan CAPTCHA dengan CapSolver
CAPTCHA adalah pertahanan utama terhadap penggalian data otomatis. Intervensi manual tidak praktis untuk operasi skala besar, membuat layanan penyelesaian CAPTCHA otomatis menjadi tidak tergantikan untuk keamanan penggalian data.
CapSolver menawarkan solusi yang kuat untuk berbagai jenis CAPTCHA, termasuk reCAPTCHA, Cloudflare Turnstile, dan tantangan berbasis gambar. Mengintegrasikan CapSolver mengotomatisasi penyelesaian CAPTCHA, memastikan pengumpulan data yang tidak terganggu. Infrastruktur berbasis AI CapSolver mengenali dan menyelesaikan CAPTCHA yang kompleks, memungkinkan scraper Anda berjalan seolah-olah pengguna manusia telah menyelesaikan tantangan tersebut. Ini berguna ketika mimikri perilaku manusia tradisional tidak cukup. Misalnya, untuk reCAPTCHA v3, CapSolver menyediakan token untuk melewati verifikasi berdasarkan penilaian risiko yang canggih, secara signifikan meningkatkan keamanan dan efisiensi penggalian data.
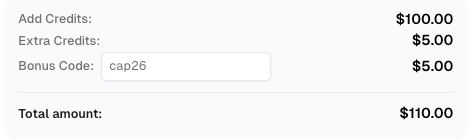
Gunakan kode
CAP26saat mendaftar di CapSolver untuk mendapatkan kredit tambahan!
Layanan CapSolver terintegrasi secara mulus ke dalam kerangka penggalian data yang ada, memberikan solusi untuk:
- reCAPTCHA v2/v3: Menyelesaikan tantangan checkbox dan reCAPTCHA yang tidak terlihat dengan menghasilkan token yang valid.
- Cloudflare Turnstile: Menyelesaikan teka-teki Cloudflare Turnstile dengan akurat, yang dirancang untuk menjaga privasi dan efektif melawan bot.
- CAPTCHA Gambar ke Teks: Menyalin teks yang terdistorsi dari gambar menggunakan teknologi pengenalan karakter optik (OCR) yang canggih.
Menggunakan layanan seperti ini meningkatkan ketahanan operasi penggalian data terhadap penghalang anti-bot yang canggih. Untuk detail integrasi, merujuk ke dokumentasi resmi, seperti Bagaimana Memilih API Penyelesaian CAPTCHA? Panduan Pembeli 2026 & Perbandingan.
Pertimbangan Hukum dan Etika
Memahami lingkungan hukum dan etika sangat penting untuk keamanan penggalian data jangka panjang. Mengabaikan aspek ini dapat menyebabkan konsekuensi serius. Menurut laporan oleh Zyte, penggalian data itu sendiri tidak ilegal secara intrinsik, tetapi kelegalannya sangat bergantung pada data yang digali dan metode yang digunakan. Selalu prioritaskan pertimbangan etika untuk menjaga reputasi yang positif dan menghindari masalah hukum.
Mematuhi robots.txt dan Ketentuan Layanan
robots.txt: File ini memberi petunjuk kepada crawler web tentang bagian mana yang harus dihindari. Selalu patuhi aturan ini. Ini adalah panduan etika yang kuat, dan mengabaikannya dapat melanggar kebijakan situs web serta mengancam keamanan penggalian data. Mematuhirobots.txtadalah aspek dasar dari penggalian yang bertanggung jawab.- Ketentuan Layanan (ToS): Situs web sering melarang pengumpulan data otomatis dalam ToS mereka. Melanggar ketentuan ini dapat menyebabkan pembatalan akun, pemblokiran IP, dan sengketa hukum. Selalu tinjau ToS sebelum memulai aktivitas penggalian untuk memastikan kepatuhan.
Privasi Data dan Kepatuhan
Ketika menggali data pribadi, kepatuhan terhadap regulasi seperti GDPR (General Data Protection Regulation) dan CCPA (California Consumer Privacy Act) sangat penting. Pastikan data yang dikumpulkan ditangani secara bertanggung jawab, di anonimkan jika diperlukan, dan hanya digunakan untuk tujuan yang sah. Ketidakpatuhan dapat menyebabkan denda besar dan konsekuensi hukum. Memprioritaskan privasi data adalah komponen penting dari keamanan penggalian data. Misalnya, International Association of Privacy Professionals (IAPP) menyoroti bagaimana hukum perlindungan data UE secara signifikan membatasi penggunaan hukum penggalian data, terutama terkait data pribadi. Selain itu, memahami kepatuhan terhadap baik GDPR dan CCPA penting bagi penggali data yang beroperasi secara global, karena regulasi ini menerapkan persyaratan ketat terhadap pengumpulan dan pemrosesan data.
Kesimpulan
Keamanan penggalian data yang efektif adalah proses terus-menerus yang beradaptasi. Dengan memahami sistem anti-bot, meniru perilaku manusia, menggunakan strategi proxy canggih, dan memanfaatkan layanan penyelesaian CAPTCHA otomatis seperti CapSolver, Anda meningkatkan ketahanan pengumpulan data. Selalu prioritaskan kepatuhan hukum dan etika, mematuhi robots.txt, ToS, dan privasi data. Tetap informasi tentang teknik anti-bot dan memantau kinerja memastikan operasi yang tidak terdeteksi. Pendekatan proaktif untuk keamanan penggalian data memungkinkan pengambilan wawasan berharga sambil mempertahankan strategi pengumpulan data yang bertanggung jawab dan berkelanjutan.
FAQ
Q1: Apakah penggalian data ilegal?
Kelegalan penggalian data kompleks, tergantung pada data yang digali, Ketentuan Layanan (ToS) situs web, dan hukum perlindungan data (misalnya, GDPR, CCPA). Secara umum, menggali data yang tersedia secara publik sering kali diperbolehkan, tetapi data yang dilindungi hak cipta atau data pribadi tanpa izin eksplisit bisa ilegal. Selalu disarankan untuk berkonsultasi dengan konsultan hukum jika Anda tidak yakin tentang kelegalan aktivitas penggalian Anda.
Q2: Bagaimana cara saya menghindari pemblokiran IP selama penggalian data?
Untuk menghindari pemblokiran IP, terapkan strategi yang mencakup rotasi IP dengan berbagai proxy (residensial, mobile), tambahkan jeda acak antara permintaan untuk meniru pola penjelajahan manusia, dan meniru perilaku browser manusia dengan header User-Agent dan Referer yang tepat. Memantau log penggalian Anda secara terus-menerus untuk aktivitas yang tidak biasa atau kode error (seperti 403 atau 429) sangat penting untuk penyesuaian proaktif dan menjaga keamanan penggalian data.
Q3: Apa itu fingerprint browser, dan bagaimana hal itu memengaruhi penggalian data?
Fingerprint browser mengumpulkan karakteristik browser yang unik seperti font yang terinstal, plugin, resolusi layar, sistem operasi, dan pengaturan bahasa untuk menciptakan identifikasi unik bagi pengguna. Sistem anti-bot menggunakan ini untuk mendeteksi browser tanpa antarmuka atau skrip otomatis yang menunjukkan fingerprint browser yang tidak konsisten atau tidak manusia. Scraper canggih harus menggunakan alat dan teknik untuk meniru fingerprint browser yang realistis dan konsisten untuk menghindari deteksi.
Q4: Bagaimana layanan penyelesaian CAPTCHA seperti CapSolver bekerja?
CapSolver menggunakan algoritma kecerdasan buatan (AI) dan pembelajaran mesin canggih untuk secara otomatis mengenali dan menyelesaikan berbagai jenis CAPTCHA. Ketika scraper Anda menemui tantangan CAPTCHA, itu mengirim tantangan tersebut ke API CapSolver. CapSolver kemudian memproses tantangan tersebut, menghasilkan solusi, dan mengembalikannya ke scraper Anda. Proses ini melewati CAPTCHA untuk pengambilan data yang tidak terganggu, secara signifikan meningkatkan efisiensi dan keandalan operasi penggalian data Anda serta memperkuat keamanan penggalian data.
Q5: Apa itu honeypots, dan bagaimana saya bisa menghindarinya?
Honeypots adalah tautan atau elemen yang disembunyikan di dalam halaman web yang dirancang untuk menangkap bot otomatis. Pengguna manusia tidak akan melihat atau berinteraksi dengan elemen ini, tetapi bot mungkin melakukannya. Untuk menghindari honeypots, scraper Anda harus menganalisis properti CSS tautan (misalnya, display: none, visibility: hidden, atau color: #fff pada latar belakang putih) dan menghindari mengikuti tautan apa pun yang disembunyikan dari pandangan manusia. Analisis yang cermat ini kritis untuk menjaga keamanan penggalian data dan menghindari deteksi serta pemblokiran langsung.
Lihat Lebih Banyak
aws wafJul 23, 2026
Cara Menyelesaikan AWS WAF di LangChain dengan CapSolver
Bangun alur kerja AWS WAF LangChain yang terotorisasi dengan alat CapSolver, deteksi respons, penghalang kebijakan, penanganan sesi, pengulangan, dan verifikasi.
AIJul 23, 2026
Cara Menyelesaikan Cloudflare Turnstile dalam Agen LangGraph
Bangun alur kerja solver Cloudflare Turnstile LangGraph dengan CapSolver, penanganan sesi Playwright, tahapan kebijakan, pengulangan, verifikasi, dan ulasan.