स्वचालन टीमों के लिए वेब स्क्रैपिंग और एपीआई के बीच शीर्ष विकल्प

Rajinder Singh
Deep Learning Researcher
TL;DR
- सबसे अच्छा वेब स्क्रैपिंग वर्सस API निर्णय डेटा के अधिकार, स्रोत उपलब्धता, विश्वसनीयता की आवश्यकता और रखरखाव लागत से शुरू होना चाहिए।
- API आमतौर पर नियंत्रित उत्पादन प्रणालियों के लिए बेहतर होते हैं क्योंकि स्कीमा, दर सीमा, प्राधिकरण और संस्करण आसानी से दस्तावेजीकृत किए जा सकते हैं।
- जब अनुमति प्राप्त सार्वजनिक डेटा के लिए उपयुक्त API उपलब्ध नहीं होता है, तो वेब स्क्रैपिंग उपयोगी होता है, लेकिन रोबोट्स.टीएक्सट समीक्षा, दर नियंत्रण, पृष्ठ-बदले की निगरानी और सुसंगतता जांच की आवश्यकता होती है।
- डायनामिक पृष्ठों के लिए ब्राउजर ऑटोमेशन मूल्य जोड़ता है, और कैपसॉल्वर अनुमोदित वर्कफ़्लो के लिए जब वे उपस्थित होते हैं, तो CAPTCHA या ट्रैफिक पुष्टि घटनाओं को हल करने में मदद कर सकता है।
- सबसे प्रतिरोधी आर्किटेक्चर API के पहले, फिर स्क्रैपिंग, आवश्यकता होने पर ब्राउजर ऑटोमेशन के बाद, और CAPTCHA हल करना एक नियंत्रित अपवाद मार्ग के रूप में होता है।
परिचय
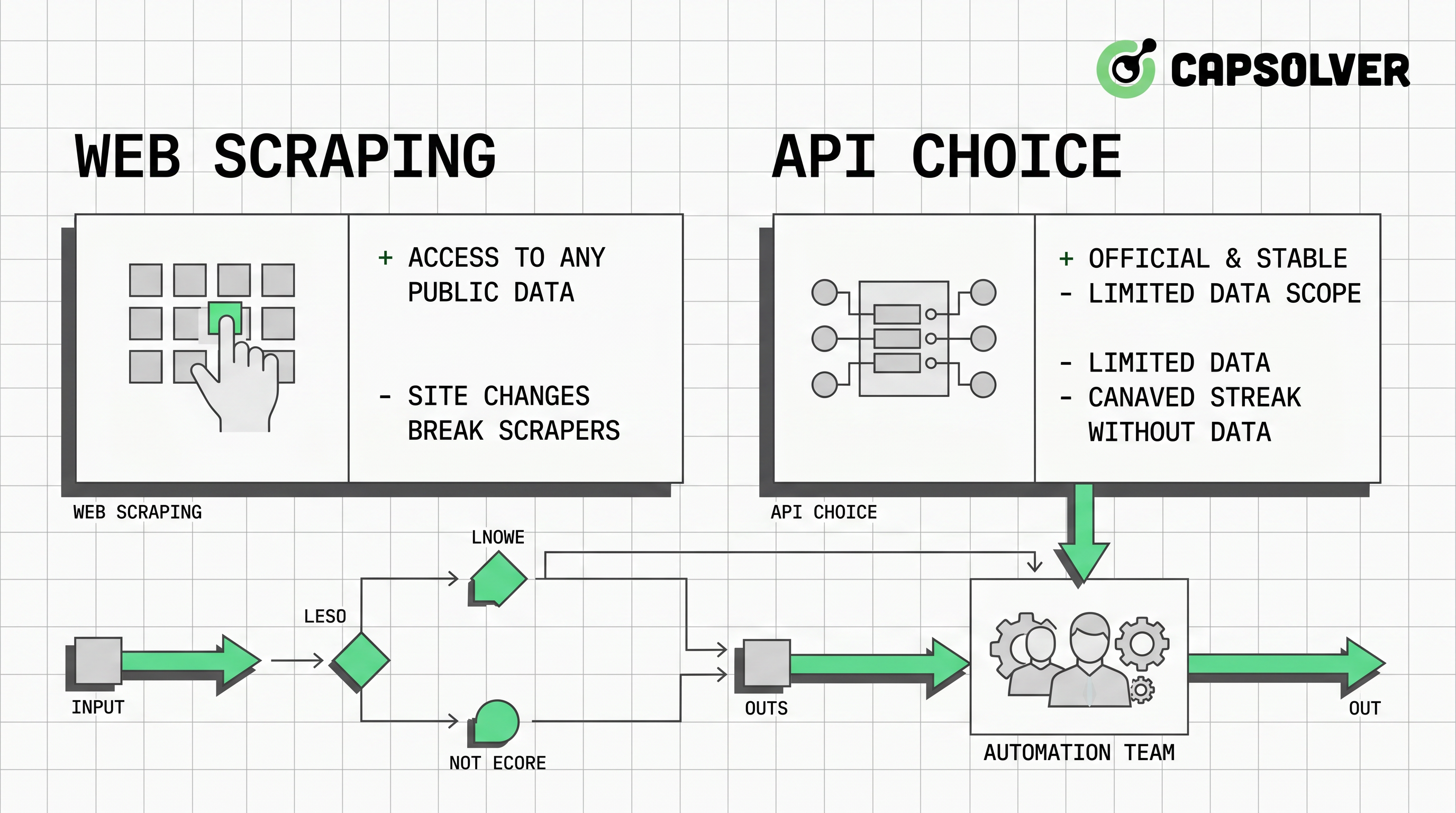
सबसे अच्छा वेब स्क्रैपिंग वर्सस API चयन आमतौर पर किस विधि की अधिक शक्ति है इस बारे में नहीं होता है। वे डेटा के लिए जिस विधि की अधिक विश्वसनीयता, अनुमति, रखरखाव और लेखापरीक्षण होती है, इस बारे में होता है जिसकी आपकी टीम को आवश्यकता होती है। API जब आवश्यक क्षेत्र, ताजगी और शर्तें प्रदान करते हैं, तो आमतौर पर पहले आते हैं। जब अनुमति प्राप्त सार्वजनिक पृष्ठ केवल व्यावहारिक स्रोत होते हैं या टीमें प्रस्तुति-स्तर पर बदलावों की निगरानी करना चाहती हैं, तो वेब स्क्रैपिंग उपयोगी होता है। अगर अनुमोदित स्क्रैपिंग या ब्राउजर ऑटोमेशन प्रवाह के दौरान CAPTCHA चुनौती का सामना करता है, तो कैपसॉल्वर के स्क्रैपिंग के दौरान CAPTCHA हल करने के गाइड एक व्यापक ऑटोमेशन प्रक्रिया में फिट होने वाले दस्तावेजीकृत हल करने के मार्ग की पेशकश कर सकता है।
API-पहला आम निर्णय होना चाहिए
API आमतौर पर आम चयन होते हैं क्योंकि वे प्रदाता-समर्थित समझौता प्रस्तुत करते हैं। एक अच्छी तरह से डिजाइन किया गया API टीमों के लिए पूर्वानुमानित क्षेत्र, प्राधिकरण, दर सीमा, त्रुटि कोड और संस्करण प्रदान करता है। इन गुणों के कारण इंजीनियरिंग समीक्षा आसान हो जाती है और भंगुर पार्सिंग की आवश्यकता कम हो जाती है। API डेटा लाइनेज को भी सरल बनाते हैं क्योंकि प्रत्येक रिकॉर्ड को एंडपॉइंट, समयचिह्न, प्रश्न पहचान या दस्तावेजीकृत स्कीमा से जोड़ा जा सकता है।
REST API ट्यूटोरियल और संदर्भ सामान्य API डिजाइन विचारों जैसे संसाधन, विधियां और प्रस्तुतियां के बारे में समझाता है। GitHub REST API दर सीमा दस्तावेजीकरण यह स्पष्ट करता है कि क्यों दर सीमा एक बाधा नहीं है बल्कि एक संचालन समझौता है। कई ऑटोमेशन कार्यक्रमों में, एक धीमा आधिकारिक API एक तेज स्क्रैपर की तुलना में बेहतर होता है क्योंकि API लेखापरीक्षण में बचाव करने में आसान होता है और जब डेटा उपभोक्ता बढ़ते हैं तो रखरखाव करने में आसान होता है।
| निर्णय कारक | API लाभ | वेब स्क्रैपिंग लाभ |
|---|---|---|
| डेटा संविदा | स्थिर स्कीमा और दस्तावेजीकृत त्रुटियां | एंडपॉइंट द्वारा उत्पन्न नहीं किए गए दृश्य क्षेत्र एकत्र कर सकते हैं |
| रखरखाव | संस्करण और समर्थन चैनल | उपयुक्त API उपलब्ध न होने पर काम करता है |
| ताजगी | पूर्वानुमानित पॉलिंग और दर सीमा | पृष्ठ-स्तर अपडेट को तेजी से प्रतिबिंबित कर सकते हैं |
| डायनामिक पृष्ठ | कम ब्राउजर अतिरिक्त | ब्राउजर ऑटोमेशन रेंडर किए गए स्थितियों की जांच कर सकता है |
| चुनौति घटनाएं | आमतौर पर बचा जाता है | नियंत्रित CAPTCHA-हल करने के कार्यप्रणाली की आवश्यकता हो सकती है |
मुख्य बात यह नहीं है कि स्क्रैपिंग को अस्वीकृत करें। मुख्य बात यह है कि ऑपरेशनल जटिलता जोड़ने से पहले स्क्रैपिंग की आवश्यकता साबित करें।
जब वेब स्क्रैपिंग बेहतर फिट होता है
जब डेटा सार्वजनिक, अनुमति, उपयुक्त API के माध्यम से उपलब्ध नहीं होता है और निगरानी के लिए पर्याप्त मूल्यवान होता है, तो वेब स्क्रैपिंग बेहतर फिट होता है। सामान्य उदाहरण सार्वजनिक मूल्य पृष्ठ, उत्पाद उपलब्धता पृष्ठ, सार्वजनिक नौकरी सूची, सार्वजनिक डायरेक्टरी और वेबसाइट बदलाव निगरानी शामिल हैं। फिर भी, टीम को डेटा क्षेत्र, स्रोत पृष्ठ, ड्रॉल आवृत्ति, अपवर्जन नियम और वर्कफ़्लो के लिए उत्तरदायी व्यावसायिक मालिक के बारे में दस्तावेजीकृत करना चाहिए।
RFC 9309 रोबोट्स अपवर्जन प्रोटोकॉल वेबसाइटों द्वारा स्वचालित ग्राहकों को बुलाने के नियमों को संचारित करने के तरीके को परिभाषित करता है। MDN URL संदर्भ डुप्लिकेट करने और ड्रॉल सीमाओं के लिए आवश्यक डुप्लिकेट करने के लिए उपयोगी है। इन संदर्भों के समर्थन से एक व्यावहारिक नियम बनता है: वेब स्क्रैपिंग को अनुमति और सीमाओं के साथ एक इंजीनियरिंग प्रणाली के रूप में व्यवहार किया जाना चाहिए, एक अनौपचारिक स्क्रिप्ट के रूप में नहीं।
वेब स्क्रैपिंग को परतदार डिजाइन के लाभ मिलते हैं। स्थिर पृष्ठ आमतौर पर HTTP मांग और पार्सर के साथ निपटाया जा सकता है। जावास्क्रिप्ट-भारी पृष्ठ ब्राउजर ऑटोमेशन के आवश्यकता हो सकती है। ट्रैफिक पुष्टि वाले पृष्ठों के लिए एक दस्तावेजीकृत चुनौति-हैंडलिंग नीति की आवश्यकता हो सकती है। कैपसॉल्वर के प्लेयराइट एकीकरण गाइड तब उपयोगी होता है जब ऑटोमेशन लेयर को निकालना और नियंत्रित चुनौति हैंडलिंग की आवश्यकता होती है।
CAPTCHA हल करना निर्णय में कहां स्थित होता है
CAPTCHA हल करना सबसे अच्छा वेब स्क्रैपिंग वर्सस API निर्णय वृक्ष में बाद में स्थित होता है। अगर API मौजूद है और आवश्यकता पूरी करता है, तो इसका उपयोग करें। अगर सार्वजनिक पृष्ठ को अनुमति प्राप्त स्थिर निकालने के माध्यम से एकत्र किया जा सकता है, तो उसका उपयोग करें। अगर ब्राउजर ऑटोमेशन की आवश्यकता होती है, तो रेंडरिंग और अंतरक्रिया नियंत्रण जोड़ें। इन चयनों के बाद ही टीम को अनुमोदित CAPTCHA या ट्रैफिक पुष्टि घटना का उपचार कैसे करना है, इसका निर्णय लेना चाहिए।
कैपसॉल्वर के reCAPTCHA शब्दावली और CAPTCHA शब्दावली दिशा-निर्देश टीमों को एक हल करने के मार्ग चुनने से पहले सामान्य चुनौति परिवारों की पहचान करने में मदद करते हैं। निर्णय में अनुमोदन शामिल होना चाहिए, समर्थित डोमेन, पुनर्प्रयास सीमा, लॉगिंग, प्रॉक्सी नीति और पृष्ठ-स्तर असफलता जांच के साथ। हल की गई चुनौति पर्याप्त नहीं है; कार्यप्रणाली को यह सुनिश्चित करना चाहिए कि अनुमोदित कार्य सही ढंग से पूरा हो गया है।
अनुमोदित डेटा ऑटोमेशन पायलट के लिए बोनस कोड
अपना कैपसॉल्वर बोनस कोड जमा करें
तुरंत अपने ऑटोमेशन बजट को बढ़ाएं!
कैपसॉल्वर खाता में अपना बोनस कोड CAP26 उपयोग करके अपने खाते को भरें ताकि प्रत्येक भरोसे पर 5% बोनस मिले — कोई सीमा नहीं।
अपने कैपसॉल्वर डैशबोर्ड में अभी जमा करें
ऑटोमेशन टीमों के लिए आर्किटेक्चर पैटर्न
एक मजबूत आर्किटेक्चर एक्सेस विधि, क्रियान्वयन, सत्यापन और शासन को अलग करता है। एक्सेस विधि एक API, स्थिर स्क्रैपर, ब्राउजर ऑटोमेशन स्क्रिप्ट या हाइब्रिड वर्कफ़्लो हो सकता है। क्रियान्वयन को दर सीमा, पुनर्प्रयास और सुरक्षित बंद शर्तों के लागू करना चाहिए। सत्यापन को रिकॉर्ड संख्या, आवश्यक क्षेत्र, स्रोत समयचिह्न और स्कीमा बदलाव की तुलना करना चाहिए। शासन को यह दर्ज करना चाहिए कि किसने स्रोत को अनुमोदित किया, कौन सा डेटा अनुमति है, और कब वर्कफ़्लो को फिर से समीक्षा करना आवश्यक होगा।
ब्राउजर-भारी वर्कफ़्लो के लिए, Playwright दस्तावेजीकरण नियंत्रित पृष्ठ रेंडरिंग और अंतरक्रिया के लिए एक व्यावहारिक शुरुआती बिंदु प्रदान करता है। क्रॉलर-भारी वर्कफ़्लो के लिए, Scrapy दस्तावेजीकरण स्पाइडर, आइटम और पाइपलाइन के बारे में समझाता है। चुनौति-भारी अनुमोदित वर्कफ़्लो के लिए, कैपसॉल्वर के ब्राउजर एक्सटेंशन गाइड इंजीनियरों के लिए वास्तविक-पृष्ठ व्यवहार की जांच करने में मदद कर सकता है जब वे एक दोहराए जा सकने वाले API-पहला मार्ग के लिए डिजाइन करते हैं।
| आर्किटेक्चर पैटर्न | इसका उपयोग कब करें | इसमें जोड़ें इस नियंत्रण |
|---|---|---|
| API-केवल | आवश्यक क्षेत्र उपलब्ध हैं और शर्तें उपयोग के लिए अनुमति देती हैं | एंडपॉइंट मॉनिटरिंग और दर-सीमा हैंडलिंग |
| स्थिर स्क्रैपिंग | सार्वजनिक पृष्ठ स्थिर और अनुमति हैं | robots.txt समीक्षा और सेलेक्टर परीक्षण |
| ब्राउजर ऑटोमेशन | रेंडरिंग या अंतरक्रिया की आवश्यकता है | समय सीमा बजट और पृष्ठ-स्थिति सत्यापन |
| हाइब्रिड API और स्क्रैपिंग | API अधिकांश क्षेत्रों को कवर करता है लेकिन पृष्ठ परिप्रेक्ष्य जोड़ता है | स्रोत-ऑफ-ट्रूथ नियम और डुप्लिकेशन निरसन |
| स्क्रैपिंग और कैपसॉल्वर | अनुमोदित पृष्ठ CAPTCHA चुनौतियां प्रस्तुत करते हैं | अनुमोदन टिकट, रेडैक्टेड लॉग और पुनर्प्रयास सीमा |
इस संरचना वेब स्क्रैपिंग वर्सस API चयन को पारदर्शी बनाती है। यह टीमों के लिए जोखिम भी कम करती है कि वे व्यवहारिक विधियां पूरा न करने से पहले ब्राउजर ऑटोमेशन या CAPTCHA हल करने को जोड़ दें।
जिम्मेदार उपयोग सूची
एक जिम्मेदार ऑटोमेशन कार्यक्रम स्रोत समीक्षा से शुरू होता है। यह सुनिश्चित करें कि डेटा सार्वजनिक है या अन्यथा अनुमति है, संग्रह उद्देश्य वैध है, और संवेदनशील व्यक्तिगत या सीमित डेटा अनुमति या कानूनी आधार और सुरक्षा नियमों के बिना बाहर है। फिर robots.txt, साइट शर्तें, API दस्तावेजीकरण और अनुबंध बाधाओं की समीक्षा करें। अंत में, कम आवृत्ति पर परीक्षण करें और अप्रत्याशित लॉगिन दीवार, अनुमति बदलाव, चुनौति बूस्ट या स्कीमा विचलन दिखाई देने पर कार्यप्रणाली बंद कर दें।
OWASP ऑटोमेटेड धांधली परियोजना एक उपयोगी याददेह रहता है कि समान ऑटोमेशन तकनीकें गलत तरीके से उपयोग की जा सकती हैं। आंतरिक मानक को अनुमति, अनुपात में मांग दर, उपयुक्त स्थान पर स्पष्ट पहचान और कार्यप्रणाली बदलने पर मानव समीक्षा की आवश्यकता होनी चाहिए। कैपसॉल्वर केवल मालिक, स्टेज्ड, ग्राहक-अनुमोदित या अन्यथा अनुमति लक्ष्यों पर उपयोग किया जाना चाहिए जहां चुनौति हल करना एक वैध ऑटोमेशन प्रक्रिया के हिस्सा है।
निष्कर्ष
सबसे अच्छा वेब स्क्रैपिंग वर्सस API निर्णय एक सरल परिवार के साथ लिया जाना चाहिए: जब आवश्यकता पूरी होती है तो API का उपयोग करें, जब नहीं तो अनुमति प्राप्त स्थिर स्क्रैपिंग का उपयोग करें, जब रेंडरिंग की आवश्यकता होती है तो ब्राउजर ऑटोमेशन का उपयोग करें, और केवल एक दस्तावेजीकृत अपवाद मार्ग के रूप में CAPTCHA हल करें। अनुमोदित ऑटोमेशन में विश्वसनीय चुनौति हल करने की आवश्यकता वाली टीमों के लिए, कैपसॉल्वर के वेब स्क्रैपिंग कानूनी गाइड आपको एपीआई, क्रॉलर, ब्राउजर ऑटोमेशन, मॉनिटरिंग और सुसंगतता समीक्षा के साथ एक नियंत्रित कार्यप्रणाली में हल करने में मदद कर सकता है।
एफक्यूएआई
वेब स्क्रैपिंग वर्सस API का सबसे अच्छा नियम क्या है?
सबसे अच्छा नियम API पहला, स्क्रैपिंग दूसरा है। जब एपीआई अपने अनुमति शर्तों के तहत डेटा प्रदान करता है, तो इसका उपयोग करें, और जब अनुमति पृष्ठ व्यावहारिक स्रोत होते हैं तो स्क्रैपिंग केवल उपयोग करें।
जब वेब स्क्रैपिंग एपीआई के मुकाबले बेहतर होता है?
जब सार्वजनिक, अनुमति पृष्ठ डेटा उपयुक्त API के माध्यम से उपलब्ध नहीं होता है, या जब पृष्ठ प्रस्तुति आपकी टीम के लिए मॉनिटर करने वाला डेटा होती है, तो वेब स्क्रैपिंग बेहतर होता है।
जब ब्राउजर ऑटोमेशन जोड़ा जाना चाहिए?
स्थिर HTTP निकालने से रेंडर किए गए सामग्री, उपयोगकर्ता अंतरक्रिया या पोस्ट-लोड डेटा को ग्रहण नहीं कर सकते हैं, तो ब्राउजर ऑटोमेशन केवल जब जोड़ा जाना चाहिए।
कैपसॉल्वर वेब स्क्रैपिंग वर्सस API वर्कफ़्लो में कैसे फिट होता है?
जब अनुमोदित वेब स्क्रैपिंग या ब्राउजर ऑटोमेशन वर्कफ़्लो के दौरान एक समर्थित CAPTCHA या ट्रैफिक पुष्टि चुनौति का सामना करता है और एक दस्तावेजीकृत हल करने के मार्ग की आवश्यकता होती है, तो कैपसॉल्वर फिट होता है।
जांचने के लिए टीम क्या जांचनी चाहिए?
टीम को अनुमति, robots.txt, शर्तें, डेटा संवेदनशीलता, मांग दर और निगरानी नियम जांचने चाहिए। वे कैपसॉल्वर के वेब स्क्रैपिंग एफक्यूएआई की समीक्षा कर सकते हैं जब चुनौति हल करना अनुमोदित योजना का हिस्सा होता है।
और देखें
Web ScrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Web ScrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।