Automatizar la resolución de CAPTCHA en navegadores sin cabeza: Guía completa del flujo de trabajo

Emma Foster
Machine Learning Engineer

TL;Dr:
- Propósito: Automatizar la resolución de CAPTCHA en entornos de navegadores headless para una automatización web eficiente.
- Pasos clave: Configuración del entorno, integración de la API (CapSolver), creación de tareas, recuperación de resultados e integración en scripts de automatización.
- Beneficios: Reduce la intervención manual, mejora la fiabilidad de la automatización y escala los esfuerzos de recolección de datos.
- CapSolver: Un servicio recomendado para resolver CAPTCHA de forma confiable y eficiente, que ofrece varios tipos de tareas y opciones de integración.
- Optimización: Implementar proxies, gestionar la frecuencia de las solicitudes y manejar errores para una automatización robusta.
Introducción
La automatización web a menudo se enfrenta a CAPTCHA, diseñados para diferenciar a los usuarios humanos de los bots automatizados. Al operar navegadores headless para tareas como raspado de datos, monitoreo o pruebas, estos desafíos pueden detener el progreso. Esta guía proporciona un flujo de trabajo completo y paso a paso para automatizar la resolución de CAPTCHA en navegadores headless, asegurando que sus procesos de automatización funcionen de manera fluida y eficiente. Cubriremos todo, desde la configuración de su entorno hasta la integración de un servicio confiable de resolución de CAPTCHA como CapSolver, procesamiento de resultados y solución de problemas comunes. Al finalizar este tutorial, tendrá el conocimiento y las herramientas para gestionar eficazmente los CAPTCHA en sus proyectos de navegadores headless, mejorando la fiabilidad y escalabilidad de sus esfuerzos de automatización web.
Comprendiendo los navegadores headless y los CAPTCHA
Los navegadores headless son navegadores web sin interfaz gráfica, comúnmente utilizados para pruebas automatizadas, raspado de datos y renderizado del lado del servidor. Ejemplos populares incluyen Puppeteer para Chrome y Playwright para varios navegadores. Aunque poderosos, su naturaleza automatizada los hace susceptibles de detección por parte de sitios web que utilizan CAPTCHA. Los CAPTCHA sirven como una capa de seguridad crítica, evitando el acceso automatizado y el uso indebido de recursos web. El desafío radica en integrar una solución que pueda resolver estos acertijos de manera confiable sin comprometer la eficiencia de sus operaciones con navegadores headless. Es aquí donde automatizar la resolución de CAPTCHA en navegadores headless se vuelve esencial.
¿Por qué aparecen los CAPTCHA en navegadores headless?
Los sitios web utilizan diversas técnicas para detectar actividad automatizada, como analizar huellas de navegadores, patrones de comportamiento del usuario y direcciones IP. Cuando estos sistemas marcan un navegador headless como no humano, se presenta un CAPTCHA. Este mecanismo está diseñado para protegerse contra spam, ataques de fuerza bruta de credenciales y extracción de datos. Para una automatización web efectiva, una estrategia sólida para automatizar la resolución de CAPTCHA en navegadores headless es indispensable.
Flujo de trabajo paso a paso para automatizar la resolución de CAPTCHA
Esta sección explica el proceso completo para integrar un servicio de resolución de CAPTCHA en su automatización de navegadores headless. Usaremos CapSolver como ejemplo debido a su API completa y soporte para varios tipos de CAPTCHA.
Paso 1: Preparación del entorno
Antes de comenzar, asegúrese de que su entorno de desarrollo esté configurado con las herramientas necesarias. Esto implica instalar una biblioteca de navegador headless y un entorno de Python para interactuar con la API de resolución de CAPTCHA.
Propósito: Establecer una base funcional para ejecutar scripts de navegadores headless e interactuar con servicios externos.
Operación:
- Instalar Python: Asegúrese de que Python 3.x esté instalado en su sistema.
- Instalar la biblioteca del navegador headless: Elija entre Puppeteer (para Node.js) o Playwright (que soporta Python, Node.js, Java, .NET). Para esta guía, asumiremos un entorno de Python con Playwright.
bash
pip install playwright playwright install - Instalar la biblioteca requests: Se usará para interactuar con la API de CapSolver.
bash
pip install requests - Obtener la clave de API de CapSolver: Regístrese en el sitio web de CapSolver y obtenga su clave de API desde el panel de control. Esta clave es crucial para autenticar sus solicitudes al servicio de resolución de CAPTCHA.
Precauciones: Siempre mantenga su clave de API segura y evite codificarla directamente en repositorios públicos. Use variables de entorno para mejores prácticas de seguridad.
Paso 2: Integración de la API de CapSolver
Con su entorno listo, el siguiente paso es integrar la API de CapSolver en su script de automatización. Esto implica enviar los detalles del CAPTCHA a CapSolver y recibir el token resuelto.
Propósito: Enviar programáticamente los desafíos de CAPTCHA a CapSolver y obtener sus soluciones.
Operación: La integración generalmente implica dos llamadas principales a la API: createTask para enviar el CAPTCHA y getTaskResult para recuperar la solución. A continuación se muestra un ejemplo en Python usando la biblioteca requests.
python
import requests
import time
# TODO: configure su clave
api_key = "SU_CLAVE_DE_API_DE_CAPSOLVER" # Reemplazar con su clave de API de CapSolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # Clave de sitio de ejemplo para demostración de reCAPTCHA v2
site_url = "https://www.google.com/recaptcha/api2/demo" # URL de ejemplo de una página con demostración de reCAPTCHA v2
def solve_recaptcha_v2_capsolver():
print("Creando tarea de CAPTCHA...")
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess', # Usando el proxy integrado del servidor
"websiteKey": site_key,
"websiteURL": site_url
}
}
try:
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print(f"Fallo al crear la tarea: {res.text}")
return None
print(f"Tarea creada con ID: {task_id}. Esperando resultado...")
while True:
time.sleep(3) # Esperar 3 segundos antes de verificar el resultado
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
print("CAPTCHA resuelto con éxito!")
return resp.get("solution", {}).get('gRecaptchaResponse')
elif status == "processing":
print("CAPTCHA aún en proceso...")
elif status == "failed" or resp.get("errorId"):
print(f"Fallo al resolver el CAPTCHA! Respuesta: {res.text}")
return None
except requests.exceptions.RequestException as e:
print(f"Fallo en la solicitud de API: {e}")
return None
# Ejemplo de uso en un script de navegador headless (conceptual)
# from playwright.sync_api import sync_playwright
# with sync_playwright() as p:
# browser = p.chromium.launch(headless=True)
# page = browser.new_page()
# page.goto(site_url)
# # Activar CAPTCHA (por ejemplo, al hacer clic en un botón o navegar a una página protegida)
# # Cuando aparezca el CAPTCHA, llamar al solucionador
# captcha_token = solve_recaptcha_v2_capsolver()
# if captcha_token:
# print(f"Token CAPTCHA recibido: {captcha_token[:30]}...")
# # Inyectar el token en la página (por ejemplo, mediante JavaScript o llenando un campo oculto)
# # page.evaluate(f"document.getElementById(\'g-recaptcha-response\').value = \'{captcha_token}\';")
# # Enviar el formulario
# else:
# print("Fallo al obtener el token CAPTCHA.")
# browser.close()Precauciones: Ajuste la duración de time.sleep() según el tiempo típico para resolver el tipo de CAPTCHA. La encuesta excesiva puede provocar limitación de tasas. Siempre maneje errores de API y problemas de red de manera adecuada.
Paso 3: Manejo del token de CAPTCHA resuelto
Una vez que CapSolver devuelve una solución, debe inyectar este token de vuelta en su sesión de navegador headless para completar el desafío de CAPTCHA.
Propósito: Enviar la solución del CAPTCHA al sitio web objetivo y continuar con la automatización.
Operación: El método para inyectar el token depende del tipo de CAPTCHA y de cómo el sitio web espere la solución. Para reCAPTCHA v2, el token se coloca típicamente en un área de texto oculta con el ID g-recaptcha-response.
python
# ... (código anterior para la función solve_recaptcha_v2_capsolver)
from playwright.sync_api import sync_playwright
# Ejemplo de uso
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(site_url)
# Esperar a que se cargue y muestre el iframe de reCAPTCHA (ajustar selectores según sea necesario)
page.wait_for_selector("iframe[title='reCAPTCHA challenge']", timeout=30000)
captcha_token = solve_recaptcha_v2_capsolver()
if captcha_token:
print(f"Token CAPTCHA recibido: {captcha_token[:30]}...")
# Inyectar el token en el campo de entrada oculto
page.evaluate(f"document.getElementById('g-recaptcha-response').value = '{captcha_token}';")
print("Token CAPTCHA inyectado. Intentando enviar el formulario...")
# Suponiendo que hay un botón de envío, hágalo clic. Ajuste el selector según sea necesario.
# page.click("button[type='submit']")
# O, si el formulario se envía automáticamente después de inyectar el token, no se necesita hacer clic.
page.wait_for_timeout(5000) # Dar tiempo suficiente para que el formulario se procese
else:
print("Fallo al obtener el token CAPTCHA. Automatización detenida.")
browser.close()Precauciones: Asegúrese de que sus selectores para el iframe de CAPTCHA y el campo de entrada oculto sean precisos. Los sitios web pueden cambiar su estructura, requiriendo actualizaciones en sus selectores. Siempre verifique que el envío del formulario sea exitoso después de inyectar el token.
Solución de problemas de problemas comunes
Incluso con una configuración robusta, podría enfrentar problemas. Aquí hay algunos problemas comunes y sus soluciones al automatizar la resolución de CAPTCHA en navegadores headless.
Problema: taskId no devuelto o errores de API
Problema: La llamada a la API createTask no devuelve un taskId o devuelve un mensaje de error.
Solución:
- Verificar clave de API: Asegúrese de que su
api_keysea correcta y tenga suficiente saldo. - Revisar el cuerpo de la solicitud: Asegúrese de que
websiteURL,websiteKeyytypeestén especificados correctamente según la documentación de la API de CapSolver para el tipo de CAPTCHA específico. - Problemas de red: Verifique su conexión a internet y asegúrese de que el punto final de la API de CapSolver sea alcanzable.
Problema: Token de CAPTCHA inválido o rechazado
Problema: CapSolver devuelve un token, pero el sitio web objetivo lo rechaza.
Solución:
- Clave de sitio y URL correctas: Estos parámetros deben coincidir exactamente con los del sitio web objetivo. Incluso pequeñas discrepancias pueden causar rechazo.
- Uso de proxies: Si el sitio web está restringido geográficamente o tiene verificaciones estrictas de IP, use un proxy con su
ReCaptchaV2Task(por ejemplo,ReCaptchaV2Taskcon parámetroproxy) que coincida con la dirección IP del navegador headless. CapSolver ofrece opciones de proxy. - Consistencia del User-Agent: Asegúrese de que la cadena User-Agent utilizada por su navegador headless coincida con la que CapSolver puede usar internamente o la que el sitio web espera. Algunos CAPTCHA avanzados verifican la consistencia.
- Cambios en el sitio web: Los sitios web actualizan con frecuencia sus implementaciones de CAPTCHA. La
websiteKeyu otros parámetros podrían haber cambiado. Use la extensión de CapSolver para obtener automáticamente los parámetros necesarios si no está seguro.
Problema: Detección del navegador headless
Problema: A pesar de resolver los CAPTCHA, el sitio web aún detecta el navegador headless y bloquea el acceso.
Solución:
- Técnicas de stealth: Implemente complementos o configuraciones de stealth para su navegador headless (por ejemplo,
puppeteer-extra-plugin-stealthpara Puppeteer, o configuraciones similares para Playwright) para imitar el comportamiento de un navegador humano. Esto incluye modificar el User-Agent, desactivar las banderas de automatización y manejar propiedades comunes del navegador que revelan automatización (consulte MDN Web Docs sobre navegadores headless). - Retrasos realistas: Introduzca retrasos similares a los humanos entre las acciones. Las acciones rápidas y consistentes son un fuerte indicador de automatización.
- Gestión de cookies y almacenamiento local: Mantenga y reutilice cookies y almacenamiento local entre sesiones para mantener un perfil de navegación consistente.
- Encabezados Referer: Asegúrese de enviar encabezados Referer adecuados con las solicitudes.
Sugerencias de optimización de rendimiento
Optimizar su flujo de trabajo de resolución de CAPTCHA es crucial para una automatización web eficiente y escalable. Considere estas sugerencias para automatizar la resolución de CAPTCHA en navegadores headless.
1. Gestión de proxies
El uso de proxies de alta calidad es vital. Los proxies residenciales o móviles suelen ser más efectivos que los proxies de centros de datos, ya que parecen tráfico de usuario legítimo. Rotar sus proxies para evitar bloqueos de IP y distribuir sus solicitudes entre diferentes direcciones IP. CapSolver admite la integración de proxies directamente dentro de su API de creación de tareas.
2. Concurrencia y frecuencia de solicitudes
Equilibre la concurrencia con la frecuencia de solicitudes. Aunque ejecutar múltiples instancias de navegadores headless simultáneamente puede acelerar las tareas, enviar demasiadas solicitudes de resolución de CAPTCHA demasiado rápido puede provocar limitación de tasas por parte del servicio de CAPTCHA o detección por parte del sitio web objetivo. Implemente retroalimentación exponencial para reintentos y retrasos dinámicos según el comportamiento observado del sitio web.
3. Almacenamiento en caché y reutilización
Para ciertos tipos de CAPTCHA o sesiones de sitio web, las soluciones podrían ser reutilizables durante un corto período. Si aplica, almacene en caché los tokens de CAPTCHA válidos y reutilícelos dentro de su ventana de validez para reducir solicitudes redundantes y costos.
Resumen de comparación: Métodos de resolución de CAPTCHA
Elegir el método adecuado para resolver CAPTCHA depende de varios factores, incluyendo costo, fiabilidad y complejidad. A continuación se muestra una comparación de enfoques comunes:
| Característica | Resolución manual | Resolución basada en OCR | Resolución basada en API (por ejemplo, CapSolver) | Aprendizaje automático (autohospedado) |
|---|---|---|---|---|
| Fiabilidad | Alta (humana) | Baja a media | Alta | Media a alta |
| Velocidad | Variable | Rápida | Rápida | Rápida |
| Coste | Mano de obra humana | Bajo (configuración) | Tarifa por resolución | Alto (configuración, mantenimiento) |
| Complejidad | Ninguno | Alto (desarrollo) | Bajo (integración de API) | Muy alto (experiencia en ML) |
| Mantenimiento | Ninguno | Alto | Bajo | Muy alto |
| Tipos de CAPTCHA | Todos | Imagen simple | Todos los tipos principales | Tipos específicos (entrenados en) |
| Escalabilidad | Bajo | Medio | Alto | Medio |
Las soluciones basadas en API como CapSolver ofrecen un equilibrio entre alta fiabilidad, velocidad y facilidad de integración, lo que las hace ideales para automatizar la resolución de CAPTCHA en navegadores sin cabeza sin un alto costo de desarrollo.
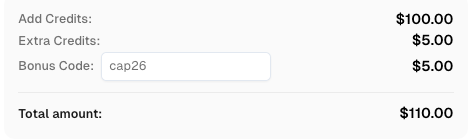
Usa el código
CAP26al registrarte en CapSolver para recibir créditos adicionales!
Conclusión
Automatizar la resolución de CAPTCHA en navegadores sin cabeza es una habilidad crítica para cualquiera involucrado en automatización web. Siguiendo el flujo de trabajo estructurado descrito en este guía, desde la configuración del entorno y la integración de API hasta el manejo de resultados y la solución de problemas, puedes mejorar significativamente la eficiencia y robustez de tus tareas automatizadas. Los servicios como CapSolver ofrecen una forma poderosa y confiable de superar los desafíos de CAPTCHA, permitiendo que tus navegadores sin cabeza operen sin interrupciones. Recuerda priorizar las consideraciones éticas y cumplir con los términos de servicio de los sitios web al implementar soluciones de automatización. Para más información sobre los desafíos de automatización web, consulta artículos como ¿Por qué la automatización web falla constantemente en CAPTCHA y Cómo extraer datos de sitios protegidos por CAPTCHA.
Preguntas frecuentes (FAQ)
P1: ¿Es legal automatizar la resolución de CAPTCHA?
R1: La legalidad de automatizar la resolución de CAPTCHA en navegadores sin cabeza depende en gran medida de los términos de servicio del sitio web y de las regulaciones locales. Aunque el acto de resolver un CAPTCHA no es inherentemente ilegal, usar automatización para acceder a contenido o realizar acciones que violen las políticas de un sitio web podría serlo. Siempre revisa los términos de servicio de los sitios web con los que interactúas.
P2: ¿Qué tipos de CAPTCHA puede manejar CapSolver?
R2: CapSolver admite una amplia gama de tipos de CAPTCHA, incluyendo reCAPTCHA v2, reCAPTCHA v3, ImageToText y varios CAPTCHA empresariales. Esta amplia compatibilidad lo convierte en una herramienta versátil para automatizar la resolución de CAPTCHA en navegadores sin cabeza en diferentes plataformas.
P3: ¿Cómo puedo reducir el costo de resolución de CAPTCHA?
R3: Para reducir costos, optimiza tus scripts de automatización para solicitar soluciones de CAPTCHA solo cuando sea absolutamente necesario. Implementa el caché para tokens reutilizables, usa intervalos eficientes para la verificación de resultados y asegúrate de que tus técnicas de stealth en navegadores sin cabeza sean robustas para minimizar la aparición de CAPTCHA desde el principio. Supervisa regularmente tu uso en CapSolver y explora sus tarifas.
P4: ¿Puedo usar CapSolver con otros lenguajes de programación?
R4: Sí, CapSolver proporciona una API RESTful, lo que significa que puede integrarse con casi cualquier lenguaje de programación capaz de realizar solicitudes HTTP. Aunque este guía usó Python, puedes adaptar fácilmente los conceptos a Node.js, Java, C#, Go u otros lenguajes. Consulta la documentación de la API de CapSolver para ejemplos específicos del lenguaje o especificaciones generales de la API.
P5: ¿Cuáles son las mejores prácticas para mantener la automatización web ética?
R5: La automatización web ética implica respetar los términos de servicio de los sitios web, evitar tasas de solicitud excesivas que puedan sobrecargar los servidores y no participar en actividades que puedan considerarse maliciosas o dañinas. Siempre busca transparencia cuando sea apropiado y considera el impacto de tu automatización en los recursos y la experiencia de los usuarios del sitio web. Enfócate en casos de uso legítimos como la recopilación de datos para investigación o uso personal, en lugar de actividades disruptivas.