Alternativas de Escrapador de IA para automatización de datos web confiables

Aloísio Vítor
Image Processing Expert
TL;DR
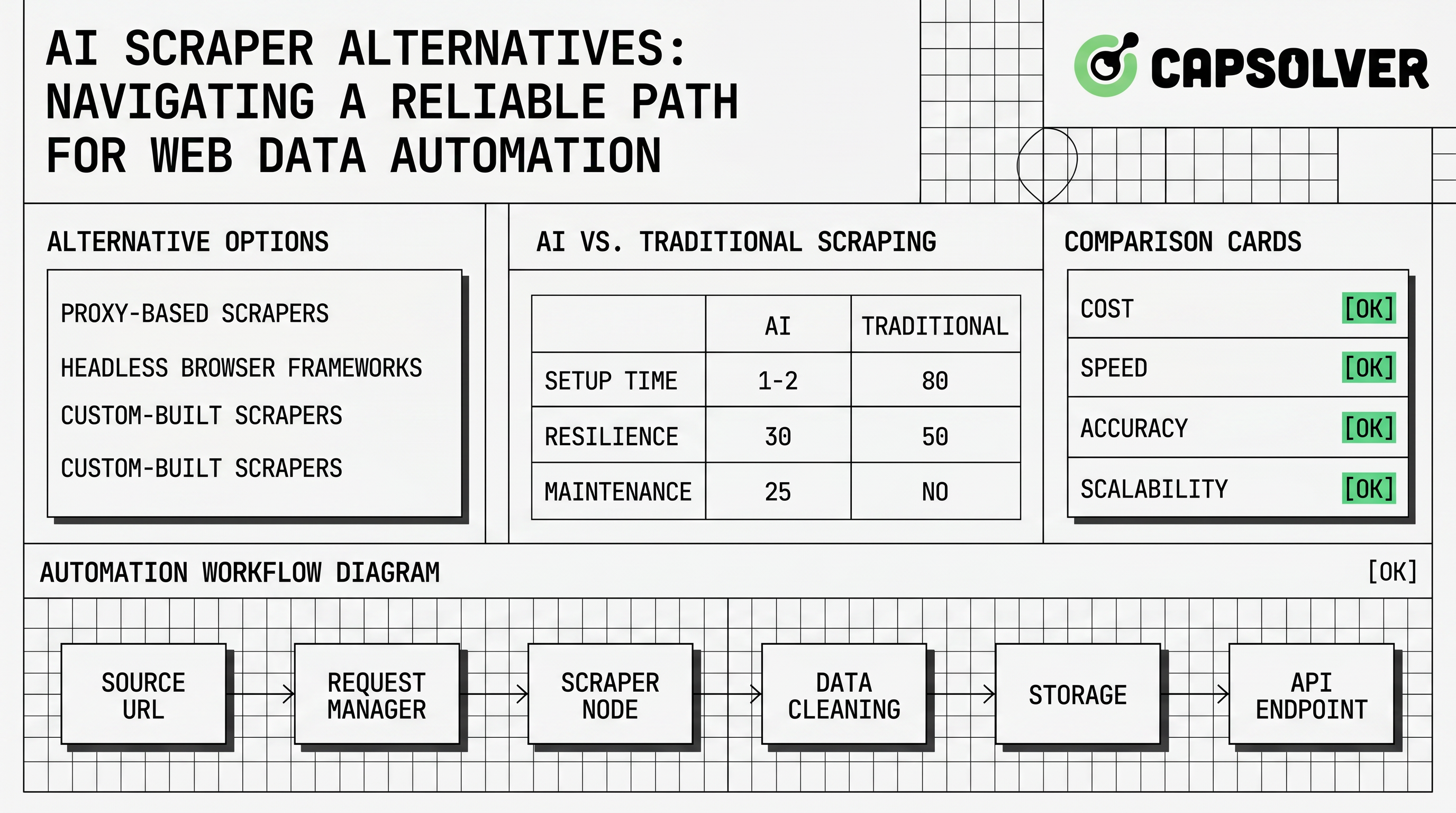
- Las alternativas a los raspadores de IA deben compararse por precisión de extracción, control de navegador, cobertura de API, controles de cumplimiento y manejo de desafíos, en lugar de solo por la interfaz.
- El flujo de trabajo más sólido suele combinar una capa de extracción de IA con raspadores deterministas, APIs oficiales, monitoreo y un camino controlado para resolver CAPTCHA en objetivos aprobados.
- La automatización de navegadores es útil para páginas dinámicas, pero los equipos deben tener límites de tasa, revisar robots.txt, verificar permisos y condiciones claras de detención antes de recopilar datos.
- Los desafíos CAPTCHA son un punto de control de confiabilidad en algunos flujos de trabajo de raspado autorizados, y CapSolver puede ayudar a los equipos a manejarlos a través de APIs documentadas y rutas de extensión de navegador.
- Los equipos deben elegir herramientas que preserven registros de auditoría, reduzcan el trabajo de mantenimiento y faciliten el uso responsable para ingenieros y operadores.
Introducción
Las alternativas a los raspadores de IA ya no son solo herramientas sin código visuales. Ahora incluyen agentes de navegador, APIs de extracción, marcos de raspador y flujos híbridos que utilizan aprendizaje automático solo donde aporta valor. La mejor elección es la que recopila datos públicos permitidos con precisión, documenta cómo se comporta el flujo de trabajo y maneja los eventos de validación de tráfico de manera responsable. Cuando la automatización aprobada alcanza un CAPTCHA u otro desafío, la guía de resolución de CAPTCHA al raspado de CapSolver puede ayudar a los equipos a definir un camino de excepción controlado en lugar de tratar la resolución como la estrategia principal. Esta guía compara opciones de enfoque en IA, enfoque en API, enfoque en navegador y híbridas para que los equipos construyan automatización de datos web confiables sin repetir patrones frágiles de raspado.
¿Qué se considera una alternativa a un raspador de IA?
Una alternativa a un raspador de IA es cualquier herramienta o arquitectura que ayude a un equipo a recopilar datos web estructurados sin depender de selectores frágiles y puntuales. Algunas herramientas utilizan modelos de lenguaje para inferir campos a partir de páginas. Otras proporcionan renderizado gestionado, raspado programado, enrutamiento de proxies o APIs de extracción listas para usar. Los marcos tradicionales también siguen siendo relevantes porque el código determinista es más fácil de auditar, probar y mantener cuando la estructura del sitio objetivo es estable.
El mercado es amplio porque las páginas web varían. Catálogos de productos, tableros de empleo, listados de viajes y directorios públicos exponen marcas, paginación, carga diferida y comportamiento de sesión diferentes. La revisión de IBM sobre raspado con IA describe el raspado con IA como el uso de IA para automatizar la extracción de datos de sitios web. La documentación de Scrapy muestra el extremo opuesto: un marco de raspador programable para extracción estructurada. Los equipos serios suelen necesitar ambos conceptos, ya que la IA puede reducir el trabajo de mapeo mientras que el código determinista mantiene la producción predecible.
| Tipo de alternativa | Mejor ajuste | Ventaja principal | Riesgo a gestionar |
|---|---|---|---|
| Herramienta de extracción de IA | Diseños cambiantes y páginas semiestructuradas | Mapeo de campos más rápido y menor esfuerzo de configuración | Desviación de salida y menor auditable |
| Automatización de navegador | Aplicaciones dinámicas y páginas con mucho JavaScript | Ejecución real de página y soporte para interacción | Mayor costo, fallas de tiempo y eventos de desafío |
| API de raspado | Renderizado gestionado y simplicidad operativa | Menor trabajo de infraestructura | Dependencia de proveedores y menos control de flujo de trabajo |
| Marco de raspador | Páginas estables y pipelines repetibles | Pruebas fuertes y control de versiones | Más trabajo de ingeniería al inicio |
| Pila híbrida | Equipos de producción con objetivos mixtos | Equilibrio entre flexibilidad y gobernanza | Requiere propiedad clara y documentación |
Las alternativas a los raspadores de IA deben seleccionarse a nivel de flujo de trabajo. Una herramienta que parece impresionante en una demostración aún puede fallar si no puede registrar aprobaciones, respetar las reglas del sitio, reintentar con seguridad o detenerse cuando una página cambie.
Criterios de evaluación para alternativas a raspadores de IA
El primer criterio es la precisión de los datos. Un raspador moderno debe devolver campos consistentes, preservar las URLs de origen y hacer visible la incertidumbre. Para la extracción basada en IA, esto significa muestrear salidas, compararlas con registros revisados por humanos y vigilar campos ficticios. Para los raspadores deterministas, significa pruebas unitarias, monitoreo de selectores y manejo claro de páginas vacías o cambiadas.
El segundo criterio es el acceso responsable. Los equipos deben revisar robots.txt, términos, disponibilidad de API, límites de tasa y permisos contractuales antes de iniciar la automatización. El Protocolo de Exclusión de Robots RFC 9309 define robots.txt como un protocolo para clientes automatizados que identifiquen reglas de acceso, mientras que la referencia de URL de MDN es útil cuando los equipos normalizan URLs canónicas y deduplican registros. La capacidad técnica no crea permiso para recopilar datos privados, sensibles, restringidos o no autorizados.
El tercer criterio es el manejo de desafíos. Algunos objetivos aprobados utilizan CAPTCHA, Cloudflare Turnstile u otros sistemas de validación de tráfico. En esos casos, la resolución de CAPTCHA debe tratarse como un camino de excepción documentado con aprobación, límites de tasa, registros enmascarados y validación de resultados. La glosario de CAPTCHA de CapSolver ayuda a los equipos a alinear terminología antes de diseñar un flujo de trabajo.
Dónde encaja la resolución de CAPTCHA en la automatización de datos web
La resolución de CAPTCHA no es el centro de una arquitectura de raspador de IA, pero puede ser una capa de confiabilidad necesaria para la automatización permitida. La secuencia correcta es simple. Primero, prefiera APIs oficiales o fuentes de datos cuando existan. Segundo, use extracción HTTP ligera cuando las páginas sean estáticas y permitidas. Tercero, use automatización de navegador solo cuando se requiera renderizado o interacción. Finalmente, agregue un camino de manejo de desafíos controlado solo cuando el flujo de trabajo esté aprobado y la página presente un paso de validación.
Por esta razón, CapSolver se introduce mejor como un componente de flujo de trabajo. La FAQ de raspado web de CapSolver da contexto a los flujos de trabajo de extracción, mientras que la guía de integración de CapSolver con Playwright muestra cómo el manejo de desafíos puede conectarse a la automatización de navegadores. El objetivo no es forzar a cada raspador a través de un servicio de resolución de desafíos. El objetivo es hacer que el camino excepcional sea consistente, auditable y más fácil de probar.
Código promocional adicional para pruebas de automatización aprobada
Redime tu código promocional de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código promocional CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
Arquitectura práctica para alternativas a raspadores de IA
Una arquitectura confiable separa el descubrimiento, la extracción, la validación y el almacenamiento. El descubrimiento identifica URLs permitidas y reglas de programación. La extracción utiliza el método de menor complejidad que funcione, como una llamada a API, un analizador HTTP, automatización de navegador o una instrucción de extracción de IA. La validación comprueba la completitud del esquema, registros duplicados, marcas de tiempo y evidencia de origen. El almacenamiento guarda instantáneas sin procesar o IDs de seguimiento cuando los equipos de cumplimiento necesiten revisar el proceso de recopilación.
Para páginas dinámicas, herramientas de navegador como la documentación de Playwright proporcionan renderizado y interacción controlados. Para pipelines de raspador, marcos como Scrapy proporcionan programación, tuberías de elementos y middleware. Para eventos de desafío, los equipos pueden referirse a la guía de extensión de navegador de CapSolver durante la depuración y luego mover flujos estables a una integración de API primero. Esto mantiene la diagnóstico humano separado de la automatización de producción repetible.
| Capa de flujo de trabajo | Control recomendado | ¿Por qué importa? |
|---|---|---|
| Revisión de permisos | Dominios aprobados y clases de datos permitidas | Evita la recopilación fuera del alcance previsto |
| Extracción | API primero, luego HTTP, luego navegador, luego análisis asistido por IA | Reduce costos y evita complejidad innecesaria |
| Manejo de desafíos | Ruta documentada de CapSolver para objetivos aprobados | Mantiene los eventos de CAPTCHA de convertirse en soluciones manuales ad-hoc |
| Monitoreo | Verificaciones de esquema y alertas de cambios en la página | Detecta desviaciones antes de que los datos incorrectos lleguen a los usuarios |
| Registro | IDs de tarea enmascarados y evidencia de origen | Facilita la auditoría sin exponer valores sensibles |
Esta arquitectura también ayuda a los equipos a decidir cuándo no usar IA. Si una página tiene marcado estable y un modelo de paginación predecible, el código determinista puede ser más confiable que un extractor basado en modelo. Si la fuente ofrece una API documentada, esa API debe generalmente preceder al raspado.
Cómo elegir la mejor opción
Elija un raspador de enfoque en IA cuando el diseño de la página cambie con frecuencia y el valor comercial justifique revisión y monitoreo. Elija un marco de raspador cuando su equipo pueda mantener código y necesite comportamiento de producción repetible. Elija una API de raspado gestionada cuando el costo de infraestructura sea el principal obstáculo. Elija automatización de navegador cuando el sitio dependa en gran medida de JavaScript o interacción similar a la del usuario. Elija CapSolver cuando un flujo de trabajo aprobado alcance un CAPTCHA o desafío de validación de tráfico compatible y el equipo necesite un camino de resolución consistente.
Los equipos de seguridad y cumplimiento deben involucrarse temprano. El proyecto de Amenazas Automatizadas de OWASP explica patrones comunes de automatización abusiva, lo que lo convierte en una lista de verificación útil para lo que los sistemas responsables deben evitar. Un raspador responsable debe identificarse cuando sea apropiado, obedecer límites, evitar datos sensibles y detenerse cuando la autorización o el comportamiento de la página sea incierto.
Conclusión
Las alternativas a los raspadores de IA deben evaluarse como modelos operativos, no solo como herramientas. Los equipos más sólidos combinan APIs oficiales, raspadores deterministas, automatización de navegador, extracción de IA, monitoreo y un camino de excepción documentado para desafíos de CAPTCHA. Si su flujo de trabajo de datos web aprobado necesita manejo confiable de desafíos como parte de esa arquitectura, la guía de raspado web responsable de CapSolver es una referencia práctica porque explica cómo encaja la resolución de CAPTCHA en la gobernanza de automatización responsable.
Preguntas frecuentes
¿Qué son las alternativas a los raspadores de IA?
Las alternativas a los raspadores de IA son herramientas o arquitecturas para la extracción de datos web, incluyendo herramientas de extracción de IA, automatización de navegador, APIs de raspado, marcos de raspador y sistemas híbridos.
¿Cuándo debe un equipo usar automatización de navegador para raspado?
Use automatización de navegador cuando las páginas objetivo permitidas requieran renderizado de JavaScript, interacción similar a la del usuario o extracción de datos posteriores a la carga que las solicitudes HTTP simples no puedan capturar de manera confiable.
¿Necesita cada raspador de IA resolver CAPTCHA?
No. La resolución de CAPTCHA solo es relevante cuando un flujo de trabajo aprobado encuentra un desafío compatible. Muchas tareas de raspado web deben usar APIs oficiales, extracción estática o alianzas de datos en lugar de CAPTCHA.
¿Cómo puede apoyar a CapSolver a las alternativas a los raspadores de IA?
CapSolver puede apoyar flujos de trabajo aprobados al manejar desafíos de CAPTCHA y validación de tráfico a través de rutas de API o extensión de navegador documentadas, especialmente en QA, monitoreo y automatización de navegador.
¿Cuál es el camino más seguro para comenzar?
Comience con la revisión de permisos, la revisión de robots.txt y un pequeño piloto. Luego compare opciones de API, raspador, navegador y extracción de IA antes de agregar el manejo de desafíos CAPTCHA donde esté claramente justificado.
Ver más
AutomationJul 07, 2026
Manejo de Captcha en la automatización de la presentación en tribunales de Legaltech
Mejorar el manejo de CAPTCHA en la automatización de presentaciones en tribunales para LegalTech: flujos de trabajo compatibles y herramientas para agilizar la presentación electrónica, reducir errores y acelerar las presentaciones.
AutomationJul 07, 2026
Cómo resolver CAPTCHA en sistemas de seguimiento de inventario de comercio electrónico
Aprende a resolver CAPTCHA en el seguimiento de inventario de comercio electrónico con métodos prácticos, consejos de automatización y cumplimiento para mantener los datos de inventario precisos y escalables.