Cómo resolver un Captcha en Crawl4AI con la integración de CapSolver

Adélia Cruz
Neural Network Developer

1. Introducción
La automatización web y la extracción de datos son vitales para muchas aplicaciones, pero los CAPTCHA a menudo interrumpen estos procesos, causando retrasos y fallos.
Para abordar este problema, Crawl4AI y CapSolver han colaborado. Crawl4AI ofrece un raspado web avanzado y adaptable, mientras que CapSolver proporciona una resolución de CAPTCHA altamente precisa y rápida. Esta colaboración permite a los desarrolladores lograr una automatización web y recolección de datos sin interrupciones.
1.1. Objetivos de la integración
Los objetivos principales de la integración entre Crawl4AI y CapSolver son:
- Combinar las capacidades eficientes de raspado de Crawl4AI con las capacidades de resolución de CAPTCHA de CapSolver: A través de una integración profunda, Crawl4AI puede llamar de forma fluida a los servicios de CapSolver cuando se encuentra con CAPTCHA, logrando un bypass automático.
- Lograr un raspado de datos web automático y sin barreras: Eliminar obstáculos causados por CAPTCHA, garantizando la continuidad y completitud de las tareas de raspado de datos, reduciendo significativamente la intervención manual.
- Mejorar la estabilidad y tasa de éxito del raspador: Proporcionar soluciones estables y confiables ante mecanismos anti-bot complejos, mejorando significativamente la tasa de éxito y eficiencia del raspado de datos.
2. Visión general de Crawl4AI
Crawl4AI es una herramienta de raspado web y extracción de datos de código abierto y amigable con modelos de lenguaje grandes (LLM), diseñada para satisfacer las necesidades de las aplicaciones de inteligencia artificial modernas. Puede transformar contenido de páginas web complejas en formato Markdown estructurado y limpio, simplificando enormemente el procesamiento y análisis posterior de los datos.
2.1. Características principales
- Amigable con LLM: Crawl4AI puede generar contenido en formato Markdown de alta calidad y soporta extracción estructurada, convirtiéndolo en una opción ideal para construir RAG (Generación Aumentada por Recuperación), agentes de IA y tuberías de datos. Automáticamente filtra el ruido, manteniendo solo la información valiosa para los LLM.
- Control avanzado del navegador: Proporciona capacidades poderosas de control de navegador sin cabeza, soportando gestión de sesiones e integración de proxies. Esto significa que Crawl4AI puede simular el comportamiento de usuarios reales, evitando eficazmente la detección de anti-bot y manejando contenido cargado dinámicamente.
- Alta rendimiento y raspado adaptativo: Crawl4AI utiliza algoritmos de raspado adaptativo inteligente que pueden determinar de forma inteligente cuándo detenerse según la relevancia del contenido, evitando el raspado ciego de grandes cantidades de páginas irrelevantes, mejorando así la eficiencia y reduciendo costos. Su velocidad y eficiencia son destacadas al manejar sitios web a gran escala.
- Modo de invisibilidad: Efectivamente evita la detección de bots imitando el comportamiento de usuarios reales.
- Raspado consciente de identidad: Puede guardar y reutilizar cookies y localStorage, soportando el raspado de sitios web tras iniciar sesión, asegurando que el raspador sea reconocido como un usuario legítimo.
2.2. Casos de uso
Crawl4AI es adecuado para el raspado a gran escala de datos como investigación de mercado, agregación de noticias o recolección de productos de comercio electrónico. Maneja sitios web dinámicos y con mucho JavaScript y sirve como fuente de datos confiable para agentes de IA y tuberías automatizadas de datos.
Crawl4AI imagina un futuro donde los datos digitales se conviertan en un activo de capital verdadero. Su whitepaper describe una economía de datos compartida, empoderando a individuos y empresas para estructurar, valorar y, opcionalmente, monetizar sus datos auténticos, alineándose estrechamente con la misión de CapSolver de liberar el valor de los datos generados por humanos a través de la resolución de CAPTCHA sin interrupciones y el acceso automatizado a datos.
3. Visión general de CapSolver
CapSolver es un servicio líder de resolución automatizada de CAPTCHA que utiliza tecnología de IA avanzada para proporcionar soluciones rápidas y precisas para diversos desafíos complejos de CAPTCHA. Su objetivo es ayudar a desarrolladores y empresas a superar las barreras de CAPTCHA y garantizar la operación fluida de procesos automatizados.
- Soporta múltiples tipos de CAPTCHA: CapSolver puede resolver tipos de CAPTCHA principales del mercado, incluyendo, pero no limitado a, reCAPTCHA v2/v3, Cloudflare Turnstile, ImageToText (OCR), AWS WAF, etc. Su amplia compatibilidad lo convierte en una solución universal para CAPTCHA.
- Alta tasa de reconocimiento y respuesta rápida: Gracias a algoritmos de IA poderosos y recursos de computación a gran escala, CapSolver logra una precisión extremadamente alta en el reconocimiento de CAPTCHA y devuelve soluciones en milisegundos, minimizando los retrasos en el raspado.
- Fácil integración de API: CapSolver proporciona interfaces de API claras y concisas y documentación detallada de SDK, facilitando que los desarrolladores integren fácilmente sus servicios en marcos de raspador existentes y herramientas de automatización, ya sea en entornos de Python, Node.js u otros lenguajes.
4. Resolviendo desafíos de CAPTCHA con Crawl4AI y CapSolver
4.1. Problemas
Antes de integrar CapSolver, incluso con sus capacidades poderosas de raspado, Crawl4AI a menudo enfrentaba los siguientes problemas al encontrarse con CAPTCHA:
- Interrupción del proceso de adquisición de datos: Una vez que el raspador activa un CAPTCHA, toda la tarea de raspado de datos se bloquea, requiriendo intervención manual para resolverlo, afectando gravemente la eficiencia de la automatización.
- Disminuida estabilidad: La aparición de CAPTCHA lleva a tareas de raspado inestables, tasas de éxito fluctuantes y dificultad para garantizar un flujo continuo de datos.
- Aumento de costos de desarrollo: Los desarrolladores deben invertir tiempo y esfuerzo adicional para encontrar, probar y mantener diversas soluciones de bypass de CAPTCHA, o resolver manualmente CAPTCHA, incrementando así los costos de desarrollo y operación.
- Compromiso de la puntualidad de los datos: Los retrasos causados por CAPTCHA pueden hacer que los datos pierdan su puntualidad, afectando decisiones basadas en datos en tiempo real.
4.2. Solución: Cómo resolver con la integración de Crawl4AI y CapSolver
La integración de Crawl4AI y CapSolver proporciona una solución elegante y poderosa que resuelve completamente los problemas mencionados anteriormente. La idea general es: cuando Crawl4AI detecta un CAPTCHA durante el proceso de raspado, activa automáticamente el servicio de CapSolver para su reconocimiento y resolución, e inyecta de forma fluida la solución en el proceso de raspado, logrando así un bypass automatizado de CAPTCHA.
Valor de la integración:
- Manejo automatizado de CAPTCHA: Los desarrolladores pueden llamar directamente a la API de CapSolver dentro de Crawl4AI, eliminando la necesidad de intervención manual y logrando el reconocimiento y resolución automatizados de CAPTCHA.
- Mejora de la eficiencia del raspado: Al evitar automáticamente los CAPTCHA, se reducen significativamente las interrupciones en el raspado, acelerando el proceso de adquisición de datos.
- Mejora de la robustez del raspador: Frente a mecanismos anti-bot diversos, la solución integrada ofrece mayor adaptabilidad y estabilidad, asegurando que el raspador funcione eficientemente en diversos entornos complejos.
- Reducción de costos operativos: Reduce la necesidad de intervención manual, optimiza la asignación de recursos y disminuye los costos operativos a largo plazo de la extracción de datos.
La integración de Crawl4AI y CapSolver principalmente implica dos métodos: integración de API e integración de extensión de navegador. La integración de API se recomienda, ya que es más flexible y precisa, evitando posibles problemas con el momento de inyección y la precisión que podrían surgir con las extensiones de navegador en páginas complejas.
5. Cómo integrar usando la API de CapSolver
La integración de API requiere combinar la funcionalidad js_code de Crawl4AI. Los pasos básicos son los siguientes:
- Navegar a la página que contiene el CAPTCHA: Crawl4AI accede normalmente a la página web objetivo.
- Obtener token usando el SDK de CapSolver: En el código Python de Crawl4AI, llame a la API de CapSolver mediante el SDK de CapSolver, enviando parámetros relacionados con el CAPTCHA (por ejemplo,
siteKey,websiteURL) al servicio de CapSolver para obtener la solución del CAPTCHA (normalmente un token). - Inyectar token usando
CrawlerRunConfigde Crawl4AI: Utilice el parámetrojs_codedel métodoCrawlerRunConfigpara inyectar el token devuelto por CapSolver en el elemento correspondiente de la página objetivo. Por ejemplo, para reCAPTCHA v2, el token normalmente necesita inyectarse en el elementog-recaptcha-response. - Continuar otras operaciones de Crawl4AI: Después de una inyección exitosa del token, Crawl4AI puede continuar realizando acciones posteriores como clics y envíos de formularios, con el CAPTCHA superado con éxito.
5.1. Resolviendo reCAPTCHA v2
reCAPTCHA v2 es un CAPTCHA común de casilla de verificación "No soy un robot". Para resolverlo, obtenga el token gRecaptchaResponse mediante CapSolver e inyéctelo en la página. Si no está seguro de cómo configurar los parámetros, consulte el blog tutorial para detectar automáticamente el CAPTCHA y extraer la configuración.
Análisis del código de ejemplo:
El código proporcionado por el usuario demuestra cómo usar el método capsolver.solve para obtener el token de reCAPTCHA v2 y asignarlo al área de texto g-recaptcha-response mediante js_code, luego simular el clic en el botón de envío. Este método asegura que el token de CAPTCHA se lleve correctamente al enviar el formulario.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: configure su configuración
# Docs: https://docs.capsolver.com/guide/captcha/ReCaptchaV2/
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de CapSolver
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9" # clave del sitio de su sitio objetivo
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php" # URL de la página de su sitio objetivo
captcha_type = "ReCaptchaV2TaskProxyLess" # tipo de CAPTCHA de su sitio objetivo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obtener token de recaptcha usando el SDK de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["gRecaptchaResponse"]
print("token de recaptcha:", token)
js_code = """
const textarea = document.getElementById(\'g-recaptcha-response\');
if (textarea) {
textarea.value = \"""" + token + """\";
document.querySelector(\'button.form-field[type="submit"]\').click();
}
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h2\');
return items.length > 1;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())Si un token v2 es inválido, obtenga la configuración JSON mediante la extensión y envíela a nuestro soporte para mejorar la puntuación del token: Resolver reCAPTCHA v2, v2 invisible, v3, v3 Enterprise ≥0.9 de puntuación.
5.2. Resolviendo reCAPTCHA v3
reCAPTCHA v3 es un CAPTCHA invisible que generalmente funciona en segundo plano y devuelve una puntuación. Antes de resolver reCAPTCHA v3, lea la documentación de reCAPTCHA v3 de CapSolver para entender los parámetros necesarios y cómo obtenerlos. Usaremos el demo de reCAPTCHA v3 como ejemplo.

-
A diferencia de v2, reCAPTCHA v3 es invisible, por lo que la inyección del token puede ser complicada. Inyectar el token demasiado pronto puede ser sobrescrito por el token original, e inyectarlo demasiado tarde puede pasar por alto el paso de verificación. En este sitio de demostración, visitar la página activa automáticamente la generación y verificación del token.
-
Al observar la página, vemos que resolver reCAPTCHA activa una solicitud fetch para verificar el token. La solución es obtener el token de CapSolver con anticipación e interceptar la solicitud fetch para reemplazar el token original en el momento adecuado.
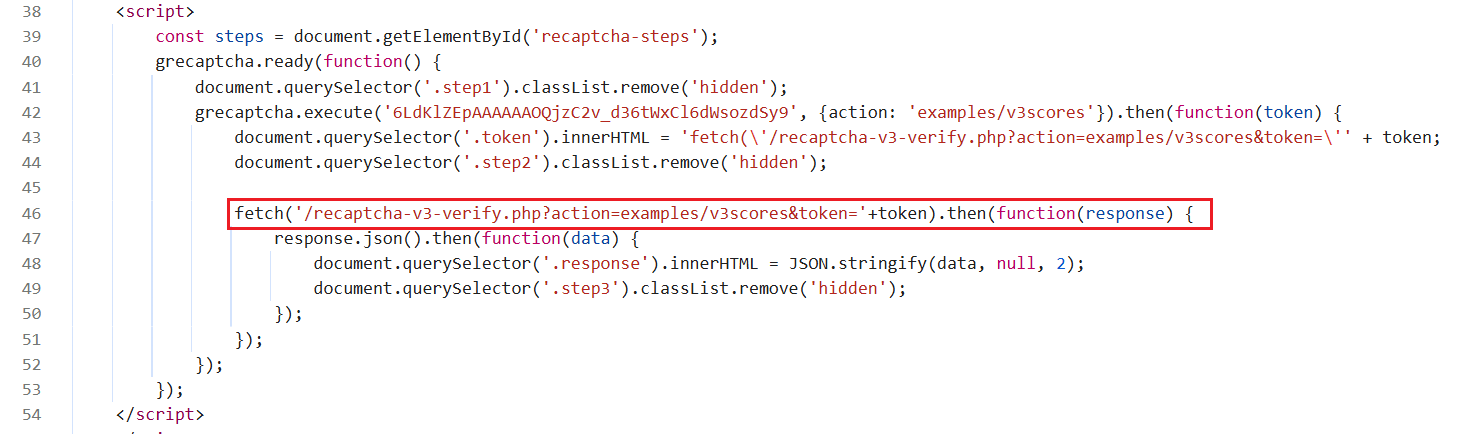
Análisis del código de ejemplo:
El código intercepta el método window.fetch, y cuando se envía una solicitud a /recaptcha-v3-verify.php, reemplaza el token de la solicitud original con el token obtenido previamente de CapSolver. Esta técnica avanzada de interceptación asegura que incluso los CAPTCHA v3 generados dinámicamente, difíciles de manipular directamente, puedan ser superados eficazmente.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: configure su configuración
# Docs: https://docs.capsolver.com/guide/captcha/ReCaptchaV3/
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de CapSolver
site_key = "6LdKlZEpAAAAAAOQjzC2v_d36tWxCl6dWsozdSy9" # clave del sitio de su sitio objetivo
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v3-request-scores.php" # URL de la página de su sitio objetivo
page_action = "examples/v3scores" # acción de página de su sitio objetivo
captcha_type = "ReCaptchaV3TaskProxyLess" # tipo de su CAPTCHA objetivo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
# obtener token de recaptcha usando el SDK de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
"pageAction": page_action,
})
token = solution["gRecaptchaResponse"]
print("token de recaptcha:", token)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
js_code = """
const originalFetch = window.fetch;
window.fetch = function(...args) {
if (typeof args[0] === 'string' && args[0].includes('/recaptcha-v3-verify.php')) {
const url = new URL(args[0], window.location.origin);
url.searchParams.set('action', '""" + token + """');
args[0] = url.toString();
document.querySelector('.token').innerHTML = "fetch('/recaptcha-v3-verify.php?action=examples/v3scores&token=""" + token + """')";
console.log('Fetch URL hooked:', args[0]);
}
return originalFetch.apply(this, args);
};
"""
wait_condition = """() => {
return document.querySelector('.step3:not(.hidden)');
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())Si un token v3 es inválido, obtenga la configuración JSON a través de la extensión y envíela a nuestro soporte para mejorar la puntuación del token: Resolver reCAPTCHA v2, reCAPTCHA invisible v2, v3, v3 Enterprise ≥0.9 score.
5.3. Resolver Cloudflare Turnstile
Antes de comenzar a resolver Cloudflare Turnstile, lea cuidadosamente la documentación de Cloudflare Turnstile de CapSolver para asegurarse de entender qué parámetros deben pasarse al crear una tarea y cómo obtener sus valores. A continuación, usaremos el demo de Turnstile como ejemplo para demostrar cómo resolver Cloudflare Turnstile.
Después de resolver Turnstile, el token se inyectará en un elemento de entrada llamado cf-turnstile-response. Por lo tanto, también nuestra js_code debe simular esta operación. Al continuar con el siguiente paso, como hacer clic en iniciar sesión, este token se llevará automáticamente para la verificación.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: configure su configuración
# Docs: https://docs.capsolver.com/guide/captcha/cloudflare_turnstile/
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de capsolver
site_key = "0x4AAAAAAAGlwMzq_9z6S9Mh" # clave del sitio de su sitio objetivo
site_url = "https://clifford.io/demo/cloudflare-turnstile" # URL de la página de su sitio objetivo
captcha_type = "AntiTurnstileTaskProxyLess" # tipo de captcha de su sitio objetivo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obtener token de turnstile usando sdk de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["token"]
print("token de turnstile:", token)
js_code = """
document.querySelector(\'input[name="cf-turnstile-response"]\').value = \'"""+token+"""\';
document.querySelector(\'button[type="submit"]\').click();
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h1\');
return items.length === 0;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())5.4. Resolver Cloudflare Challenge
Cloudflare Challenge generalmente requiere un manejo más complejo, incluyendo la coincidencia de huellas de navegador y User-Agent. CapSolver proporciona el tipo AntiCloudflareTask para resolver estos desafíos. Antes de resolver un desafío de Cloudflare, por favor revise la documentación de Cloudflare Challenge de CapSolver para entender los parámetros necesarios y cómo obtenerlos al crear una tarea.
Notas:
- La versión del navegador, la plataforma y el userAgent deben coincidir con la versión utilizada por CapSolver.
- El userAgent debe ser consistente con la versión y la plataforma.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: configure su configuración
# Docs: https://docs.capsolver.com/guide/captcha/cloudflare_challenge/
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de capsolver
site_url = "https://gitlab.com/users/sign_in" # URL de la página de su sitio objetivo
captcha_type = "AntiCloudflareTask" # tipo de su captcha objetivo
# su proxy http para resolver el desafío de cloudflare
proxy_server = "proxy.example.com:8080"
proxy_username = "myuser"
proxy_password = "mypass"
capsolver.api_key = api_key
async def main():
# obtener cookie de desafío usando sdk de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": f"{proxy_server}:{proxy_username}:{proxy_password}",
})
cookies = solution["cookies"]
user_agent = solution["userAgent"]
print("cookies de desafío:", cookies)
cookies_list = []
for name, value in cookies.items():
cookies_list.append({
"name": name,
"value": value,
"url": site_url,
})
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_agent=user_agent,
cookies=cookies_list,
proxy_config={
"server": f"http://{proxy_server}",
"username": proxy_username,
"password": proxy_password,
},
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())5.5. Resolver AWS WAF
AWS WAF es un Firewall de Aplicaciones Web que generalmente verifica las solicitudes estableciendo cookies específicas. Para más información sobre cómo lidiar con AWS WAF, consulte nuestro guía en la documentación de AWS WAF para asegurarse de que sepa qué tipos de parámetros deben enviarse al crear una tarea y cómo obtenerlos. La clave para resolver AWS WAF es obtener la cookie aws-waf-token devuelta por CapSolver.
Análisis del código de ejemplo:
El código obtiene la cookie aws-waf-token a través de CapSolver, luego usa js_code para establecerla como una cookie de página y recarga la página. Después de recargar, Crawl4AI accederá a la página con la cookie correcta, evitando así la detección de AWS WAF.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: configure su configuración
# Docs: https://docs.capsolver.com/guide/captcha/awsWaf/
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de capsolver
site_url = "https://nft.porsche.com/onboarding@6" # URL de la página de su sitio objetivo
cookie_domain = ".nft.porsche.com" # el nombre de dominio al que desea aplicar la cookie
captcha_type = "AntiAwsWafTaskProxyLess" # tipo de su captcha objetivo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obtener cookie de aws waf usando sdk de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
})
cookie = solution["cookie"]
print("cookie de aws waf:", cookie)
js_code = """
document.cookie = \'aws-waf-token=""" + cookie + """;domain=""" + cookie_domain + """;path=/\';
location.reload();
"""
wait_condition = """() => {
return document.title === \'Unirse al viaje de Porsche en Web3\';
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())6. Cómo integrar usando la extensión de CapSolver
Integrar una extensión de navegador con crawl4ai requiere especificar el directorio de inicio del navegador, luego instalar la extensión para resolver captchas. Puede elegir que la extensión los resuelva automáticamente o use js_code para la resolución activa. Los pasos generales son los siguientes:
- Iniciar el navegador especificando el
user_data_dir. - Instalar la extensión: Visite
chrome://extensions, haga clic en "Modo de desarrollador" en la esquina superior derecha, luego seleccione "Cargar extensión sin empaquetar" y elija el directorio local del proyecto de la extensión. - Visite la página de la extensión de CapSolver y configure la clave de API; alternativamente, configure el
apiKeydirectamente en/CapSolver/assets/config.jsdentro del proyecto de la extensión.
Descripción de parámetros deconfig.js:
useCapsolver: Si se debe usar automáticamente CapSolver para detectar y resolver captchas.manualSolving: Si se debe iniciar manualmente la resolución de captcha.useProxy: Si se debe configurar un proxy.enabledForBlacklistControl: Si se debe habilitar el control de lista negra.- ...
- Visite una página que contenga un captcha.
- Espere a que la extensión procese automáticamente / use
js_codepara elegir cuándo resolver el captcha. - Continúe con otras operaciones usando crawl4ai.
Los siguientes ejemplos mostrarán cómo resolver reCAPTCHA v2/v3, Cloudflare Turnstile, AWS WAF a través de la integración con la extensión.
6.1. Resolver reCAPTCHA v2
Antes de resolver reCAPTCHA v2, asegúrese de que haya configurado correctamente la extensión. A continuación, usaremos la API de demostración como ejemplo para demostrar cómo resolver reCAPTCHA v2.
Después de resolver reCAPTCHA, al continuar con el siguiente paso, como hacer clic en iniciar sesión, la verificación ocurrirá automáticamente.
python
import time
import asyncio
from crawl4ai import *
# TODO: el directorio de datos de usuario que incluye la extensión capsolver
user_data_dir = "/browser-profile/Default1"
"""
La extensión capsolver admite más funciones, como:
- Decirle a la extensión cuándo comenzar a resolver el captcha.
- Llamar a funciones para verificar si el captcha ha sido resuelto, etc.
Blog de referencia: https://docs.capsolver.com/guide/automation-tool-integration/
"""
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# hacer algo más tarde
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())Si necesita resolver activamente el captcha, use el siguiente código:
- Nota: Haga clic en "Resolver manualmente" en la página de la extensión.
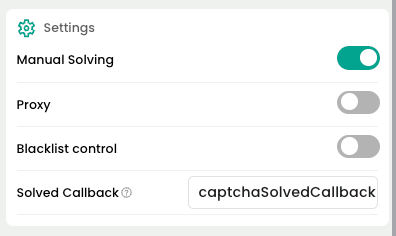
Debe configurar el parámetro manualSolving de la extensión en true. De lo contrario, la extensión activará automáticamente la resolución del captcha.
python
import time
import asyncio
from crawl4ai import *
# TODO: el directorio de datos de usuario que incluye la extensión capsolver
user_data_dir = "/browser-profile/Default1"
"""
La extensión capsolver admite más funciones, como:
- Decirle a la extensión cuándo comenzar a resolver el captcha.
- Llamar a funciones para verificar si el captcha ha sido resuelto, etc.
Blog de referencia: https://docs.capsolver.com/guide/automation-tool-integration/
"""
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# hacer algo más tarde
time.sleep(6)
js_code = """
let solverButton = document.querySelector(\'#capsolver-solver-tip-button\');
if (solverButton) {
// evento de clic
const clickEvent = new MouseEvent(\'click\', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
config=run_config
)
print("Resultados de ejecución de JS:", result_next.js_execution_result)
if __name__ == "__main__":
asyncio.run(main())6.2. Resolver reCAPTCHA v3
Antes de resolver reCAPTCHA v3, asegúrese de que haya configurado correctamente la extensión. A continuación, usaremos la API de demostración como ejemplo para demostrar cómo resolver reCAPTCHA v3.
Después de resolver reCAPTCHA, al continuar con el siguiente paso, como hacer clic en iniciar sesión, la verificación ocurrirá automáticamente.
- Se recomienda resolver reCAPTCHA v3 automáticamente mediante la extensión, generalmente desencadenado al visitar el sitio web.
La extensión capsolver admite más funciones, como:
- Informar a la extensión cuándo iniciar la resolución de CAPTCHA.
- Llamar a funciones para verificar si el CAPTCHA ha sido resuelto, etc.
Blog de referencia: https://docs.capsolver.com/guide/automation-tool-integration/
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v3-request-scores.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# hacer algo más tarde
time.sleep(300)if name == "main":
asyncio.run(main())
### 6.3. Resolviendo Cloudflare Turnstile
Antes de resolver Cloudflare Turnstile, asegúrese de que haya configurado correctamente la extensión. A continuación, usaremos <a href="https://clifford.io/demo/cloudflare-turnstile" rel="nofollow">Demo de Turnstile</a> como ejemplo para demostrar cómo resolver Cloudflare Turnstile.
Después de resolver Turnstile, se inyectará un token en un elemento de entrada con el nombre `cf-turnstile-response`. Al continuar con el siguiente paso, como hacer clic en iniciar sesión, este token se llevará automáticamente para la verificación.
```python
import time
import asyncio
from crawl4ai import *
# TODO: el directorio de datos de usuario que incluye la extensión capsolver
user_data_dir = "/browser-profile/Default1"
"""
La extensión capsolver admite más funciones, como:
- Informar a la extensión cuándo iniciar la resolución de CAPTCHA.
- Llamar a funciones para verificar si el CAPTCHA ha sido resuelto, etc.
Blog de referencia: https://docs.capsolver.com/guide/automation-tool-integration/
"""
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://clifford.io/demo/cloudflare-turnstile",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# hacer algo más tarde
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())6.4. Resolviendo AWS WAF
Antes de resolver AWS WAF, asegúrese de que la extensión CapSolver esté configurada correctamente. En este ejemplo, usaremos demo de AWS WAF para demostrar el proceso.
Una vez resuelto AWS WAF, se obtendrá una cookie llamada aws-waf-token. Esta cookie se llevará automáticamente para la verificación en operaciones posteriores.
python
import time
import asyncio
from crawl4ai import *
# TODO: el directorio de datos de usuario que incluye la extensión capsolver
user_data_dir = "/browser-profile/Default1"
"""
La extensión capsolver admite más funciones, como:
- Informar a la extensión cuándo iniciar la resolución de CAPTCHA.
- Llamar a funciones para verificar si el CAPTCHA ha sido resuelto, etc.
Blog de referencia: https://docs.capsolver.com/guide/automation-tool-integration/
"""
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# hacer algo más tarde
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())7. Conclusión
La colaboración oficial entre Crawl4AI y CapSolver marca un hito significativo en el campo de la extracción de datos web. Al combinar las capacidades eficientes de raspado de Crawl4AI con los servicios poderosos de resolución de CAPTCHA de CapSolver, los desarrolladores ahora pueden construir sistemas de raspado automatizados más estables, eficientes y robustos.
Ya sea con contenido dinámico complejo o diversos mecanismos anti-bot, esta solución integrada ofrece un excelente rendimiento y flexibilidad. La integración de API proporciona un control detallado y mayor precisión, mientras que la integración de extensión del navegador simplifica el proceso de configuración, adaptándose a las necesidades de diferentes escenarios.
7.1. Preguntas frecuentes
P1: ¿Qué es la integración de Crawl4AI y CapSolver y cómo resuelve CAPTCHAs?
R1: La integración combina el raspado web avanzado de Crawl4AI con la resolución automatizada de CAPTCHAs de CapSolver. Evita CAPTCHAs como reCAPTCHA v2/v3, Cloudflare Turnstile y AWS WAF, permitiendo la extracción de datos web ininterrumpida y eficiente sin intervención manual.
P2: ¿Cuáles son los principales beneficios para el raspado web?
R2: Los beneficios clave incluyen el manejo automático de CAPTCHAs, raspado más rápido y confiable, mayor robustez frente a mecanismos anti-bot y menores costos operativos al reducir la resolución manual de CAPTCHAs.
P3: ¿Cómo maneja diferentes tipos de CAPTCHA?
R3: Usando métodos de API y extensión del navegador, resuelve:
- reCAPTCHA v2: token inyectado en la página
- reCAPTCHA v3: hook de fetch reemplaza tokens dinámicamente
- Cloudflare Turnstile: token inyectado en campo de entrada
- AWS WAF: cookie válida obtenida
Esto asegura un bypass integral para diversos desafíos.
P4: ¿Cuáles son las funciones principales de Crawl4AI para IA y extracción de datos?
R4: Crawl4AI proporciona contenido estructurado en Markdown para agentes de IA, control avanzado del navegador con gestión de proxy y sesión, raspado de alto rendimiento adaptativo, modo de invisibilidad para evitar la detección de bots y raspado consciente de identidad para sesiones iniciadas.
7.2. Documentaciones
Ver más
Web ScrapingJul 22, 2026
Monitoreo de Regresión en SEO Técnico: Pipeline de Automatización
Construir un monitoreo de regresión de SEO técnico con líneas base versionadas, diferencias semánticas, alertas verificadas y un paso opcional de recuperación CAPTCHA autorizado.

CloudflareJul 22, 2026
Solucionador de CAPTCHA MCP: Guía de Integración de Cloudflare Turnstile
Construya un flujo de trabajo de MCP de Cloudflare Turnstile con CapSolver, reintentos limitados, registros con datos eliminados, verificaciones de sesión y validación de resultados.