Seguridad del Web Scraping: Mejores Prácticas para Proteger los Datos y Evitar la Detección

Aloísio Vítor
Image Processing Expert

TL;DR:
- Cumplimiento legal y ético: Cumple con
robots.txty los términos de servicio para una recopilación de datos ética. - Simular comportamiento humano: Implementa retrasos, rota agentes de usuario y gestiona cookies para evitar la detección de bots.
- Utilizar proxies: Emplea tipos de proxies diversos (residenciales, de centro de datos) para distribuir las solicitudes y enmascarar tu IP.
- Manejar CAPTCHAs: Integra servicios de resolución automática de CAPTCHAs para una recopilación de datos ininterrumpida.
- Monitorear y adaptarse: Supervisa continuamente el rendimiento de la extracción de datos y los cambios en el sitio web para mantener la efectividad.
Introducción
El raspado web, una técnica poderosa para extraer datos, presenta desafíos significativos de seguridad y riesgos de detección. Esta guía presenta buenas prácticas para la seguridad del raspado web, ayudando a los profesionales de los datos a proteger sus datos y navegar por los sistemas anti-bot. Comprender los mecanismos de detección e implementar estrategias sólidas asegura una recopilación de datos eficiente, ética e ininterrumpida. Clarificamos conceptos, establecemos conocimientos fundamentales y ofrecemos soluciones prácticas para mejorar tus operaciones de raspado web. Para profundizar en los fundamentos, explore ¿qué es el raspado web.
Entendiendo la seguridad del raspado web: ¿Qué, por qué y cómo?
El raspado web seguro y efectivo requiere comprender cómo los sitios web protegen su información. La seguridad del raspado web implica métodos y prácticas para evitar que los raspadores sean detectados, bloqueados o enfrenten problemas legales. El objetivo es recopilar datos respetando las políticas del sitio web y evitando activar los mecanismos anti-bot. Esto equilibra la eficiencia con la discreción, haciendo que las actividades de raspado parezcan interacciones legítimas de usuarios.
La esencia de la detección del raspado web
Los sitios web utilizan diversas técnicas para identificar y disuadir el raspado automatizado. Los mecanismos de detección analizan patrones que se desvían del comportamiento típico de los humanos. Tasas de solicitud altas desde una sola IP o encabezados de navegador faltantes pueden marcar rápidamente a un raspador. Comprender estos disparadores es crucial para estrategias de raspado resilientes. Las tecnologías anti-bot evolucionan constantemente, requiriendo una adaptación continua de las prácticas de seguridad del raspado web.
Cómo funcionan los sistemas anti-bot
Los sistemas anti-bot analizan numerosos puntos de datos de las solicitudes entrantes, construyendo un perfil de visitante y buscando anomalías. Indicadores clave incluyen la reputación de la IP, el fingerprint del navegador, los encabezados de solicitud y los patrones de comportamiento. Desviaciones significativas de un perfil humano pueden desencadenar respuestas como desafíos de CAPTCHA o bloqueos de IP. La seguridad del raspado web efectiva busca integrarse con el tráfico legítimo, dificultando que estos sistemas los diferencien.
Conocimiento estructurado: Definiciones, clasificaciones y escenarios
Construir una base sólida en la seguridad del raspado web requiere categorizar componentes y comprender sus roles. Este enfoque estructurado ayuda a identificar medidas correctivas adecuadas para diferentes desafíos de raspado.
Conceptos clave en la seguridad del raspado web
- Rotación de IP: Cambiar las direcciones IP para las solicitudes para evitar límites de velocidad y bloqueos de IP, haciendo que las solicitudes parezcan provenir de usuarios distintos. Esta técnica es fundamental para distribuir la carga de solicitudes y evitar que una sola IP sea marcada.
- Gestión del Agente de usuario: Establecer encabezados
User-Agentadecuados para simular navegadores web populares, ya que los sistemas anti-bot verifican esto para su legitimidad. Rotar regularmente los Agentes de usuario puede mejorar aún más la discreción. - Ralentización de solicitudes: Introducir retrasos entre solicitudes para simular patrones de navegación humana y evitar sobrecargar el servidor. Aleatorizar estos retrasos hace que la actividad de raspado parezca más natural.
- Fingerprint del navegador: Recopilar características únicas del navegador (por ejemplo, complementos, fuentes, resolución de pantalla) para identificar y rastrear usuarios. Los sistemas anti-bot avanzados utilizan esto para detectar navegadores sin interfaz gráfica. Los raspadores deben presentar fingerprints de navegador consistentes y comunes.
- CAPTCHA (Prueba Turing automatizada pública para diferenciar computadoras y humanos): Un test de desafío-respuesta para verificar usuarios humanos. Existen varios tipos con lógica de reconocimiento diferente, representando un obstáculo significativo para los sistemas automatizados.
Clasificación de medidas anti-bot
Los sitios web implementan defensas en capas contra los raspadores:
- Límites de velocidad: Restringir las solicitudes desde una sola IP dentro de un período de tiempo. Exceder los límites suele resultar en bloqueos temporales o permanentes.
- Lista negra de IPs: Bloquear direcciones IP o rangos conocidos como maliciosos basándose en datos históricos o inteligencia de amenazas. Por eso, el uso de proxies diversos es crítico.
- Desafíos de CAPTCHA: Presentar acertijos visuales o interactivos para verificar la interacción humana (por ejemplo, reCAPTCHA, Cloudflare Turnstile). Estos están diseñados para ser difíciles de resolver automáticamente para los bots.
- Verificación de Agentes de usuario y encabezados: Validar las cadenas
User-Agenty otros encabezados HTTP para que se parezcan a navegadores legítimos. Encabezados inconsistentes o obsoletos pueden marcar rápidamente a un bot. - Pozos de miel: Enlaces o elementos invisibles diseñados para atrapar bots automatizados. Seguirlos marca al raspador como no humano, llevando a un bloqueo inmediato.
- Desafíos de JavaScript: Requerir la ejecución de JavaScript para renderizar contenido o resolver acertijos computacionales, disuadiendo a los raspadores simples que no ejecutan JavaScript.
- Fingerprint del navegador: Analizar características sutiles del navegador para identificar herramientas automatizadas. Esto incluye comprobar inconsistencias en las propiedades del navegador que podrían indicar un navegador sin interfaz gráfica.
Escenarios de uso para el raspado seguro
El raspado web seguro es vital para diversas aplicaciones, incluyendo investigación de mercado, agregación de contenido e inteligencia competitiva. Por ejemplo, un negocio de comercio electrónico que raspa precios de competidores necesita un perfil bajo para evitar bloqueos y recopilar datos precisos en tiempo real. Los investigadores académicos que recopilan datos públicos deben asegurar métodos compatibles para evitar problemas legales y éticos. Los principios de seguridad del raspado web se aplican universalmente, independientemente de los objetivos de recopilación de datos, destacando la necesidad de estrategias sólidas para garantizar la integridad de los datos y la continuidad operativa.
Fundamento técnico: Tipos de CAPTCHA, lógica de reconocimiento y control de riesgos
Los CAPTCHA son un obstáculo significativo, diseñados para diferenciar usuarios humanos de bots. Comprender su base técnica es clave para superarlos. La tecnología CAPTCHA evoluciona constantemente para contrarrestar la resolución automatizada.
Tipos comunes de CAPTCHA y su lógica
- reCAPTCHA (Google): Evolucionó desde la reconocimiento de texto simple (v1) al análisis de comportamiento y puntuaciones de riesgo (v2 "No soy un robot" checkbox, reCAPTCHA invisible) y análisis de fondo invisible (v3). La lógica de v2 y v3 depende fuertemente de los patrones de interacción del usuario, el fingerprint del navegador y la reputación de la IP. Una historia de navegación limpia, movimientos del mouse típicos y un comportamiento consistente reducen la probabilidad de ser desafiado.
- Cloudflare Turnstile: Una alternativa de reCAPTCHA enfocada en la privacidad, a menudo usando desafíos basados en imágenes o verificación pasiva. Su lógica se centra en la precisión y consistencia de las selecciones del usuario o señales de comportamiento sin requerir interacción explícita del usuario en muchos casos.
- CAPTCHA basado en imágenes: Estos requieren identificar objetos, caracteres o patrones dentro de un conjunto de imágenes. La lógica de reconocimiento utiliza coincidencia de patrones visuales, lo que es difícil para los bots sin capacidades avanzadas de visión por computadora.
- CAPTCHA de audio: Presentan clips de audio distorsionados de números o letras para transcripción. Los bots suelen tener dificultades con la distorsión, el ruido de fondo y los acentos variados, lo que los hace efectivos contra solucionadores automatizados simples.
Lógica de reconocimiento y control de riesgos
Los sistemas anti-bot, incluidos aquellos que implementan CAPTCHA, utilizan mecanismos de control de riesgos sofisticados. Analizan numerosos factores en tiempo real para evaluar la probabilidad de que una solicitud provenga de un bot:
- Análisis de comportamiento: Implica examinar movimientos del mouse, entradas del teclado, patrones de desplazamiento y tiempo dedicado a una página. Acciones inconsistentes o excesivamente precisas, o acciones demasiado rápidas o lentas, pueden marcar un bot.
- Características de red: Factores como la reputación de la IP, el país de origen y el uso de VPNs o proxies conocidos se evalúan. Las IPs asociadas con actividades maliciosas o centros de datos suelen ser marcadas con mayor frecuencia.
- Entorno del navegador: Discrepancias en las cadenas
User-Agent, complementos faltantes, entornos inusuales de ejecución de JavaScript o inconsistencias en las resoluciones de pantalla reportadas pueden indicar un navegador sin interfaz gráfica o un script automatizado. - Frecuencia y volumen de solicitudes: Solicitudes anormalmente altas desde una sola fuente en un corto período, mucho más allá de los patrones típicos de navegación humana, son un fuerte indicador de actividad automatizada.
Los factores acumulados de riesgo escalan las respuestas, llevando a desafíos de CAPTCHA más estrictos, limitación de velocidad o bloqueo directo de la IP. Las estrategias de seguridad del raspado web buscan minimizar estos factores, haciendo que los raspadores parezcan usuarios humanos legítimos.
Flujo de proceso simple para el raspado web seguro
Una comprensión de alto nivel del proceso de raspado web seguro es beneficiosa para implementar medidas correctivas efectivas.
-
Configuración inicial y configuración:
- Elija un proveedor de proxies confiable: Seleccione un servicio que ofrezca tipos de IP diversos (residenciales, móviles) y rotación. Esto es fundamental para la seguridad del raspado web, ya que ayuda a distribuir las solicitudes y enmascarar tu dirección IP real.
- Configure la rotación de
User-Agent: Mantenga cadenasUser-Agentactualizadas y rotelas por solicitud o sesión. Esto simula entornos de usuario diversos y evita la detección basada en unUser-Agentestático. - Implemente retrasos en las solicitudes: Introduzca retrasos aleatorios entre solicitudes (por ejemplo, 2-10 segundos) para simular la velocidad de navegación humana. Evite retrasos predecibles, como los fijos, que pueden detectarse fácilmente.
-
Verificaciones previas al raspado:
- Revise
robots.txt: Siempre verifique el archivorobots.txtdel sitio web objetivo (https://example.com/robots.txt) para políticas de raspado. Respetar estas pautas es crucial para el cumplimiento ético y legal. Ignorarrobots.txtpuede llevar a problemas legales y bloqueos de IP. Esto es un aspecto fundamental de la seguridad del raspado web responsable. - Analice la estructura del sitio web: Entienda la estructura HTML e identifique posibles pozos de miel (por ejemplo, elementos con
display: noneovisibility: hidden) para evitar interactuar con ellos. Interactuar con pozos de miel es una señal clara de actividad automatizada.
- Revise
-
Ejecución y monitoreo:
- Raspe datos: Ejecute su script, siguiendo los retrasos configurados y la rotación de proxies.
- Monitoree los bloqueos: Supervise continuamente las tasas de éxito de las solicitudes y los códigos de estado HTTP. Si ocurren bloqueos (por ejemplo, códigos HTTP 403, 429 o páginas de CAPTCHA), analice la respuesta para identificar la causa. Para estrategias sobre cómo evitar el bloqueo de IP, consulte nuestra guía detallada.
- Adapte y refina: Ajuste los parámetros de raspado (por ejemplo, aumente los retrasos, cambie los tipos de proxy, actualice las cadenas
User-Agent) basándose en el monitoreo en tiempo real y la retroalimentación de las respuestas del sitio web.
-
Post-raspado y manejo de datos:
- Validación de datos: Verifique la precisión, completitud y consistencia de los datos extraídos. Implemente verificaciones para asegurar que los datos estén limpios y sean utilizables.
- Almacenamiento y seguridad: Almacene los datos recopilados de forma segura, siguiendo regulaciones de protección de datos relevantes como el RGPD y CCPA. Asegúrese de que los datos estén encriptados y el acceso esté restringido a personal autorizado.
Soluciones para mejorar la seguridad del raspado web
A medida que las tecnologías anti-bot avanzan, también deben hacerlo las estrategias de raspado web seguro. Estas soluciones abordan desafíos comunes y proporcionan caminos para una recopilación de datos resistente.
Simular comportamiento humano
Hacer que tu raspador se comporte como un usuario humano es altamente efectivo contra la detección:
- Retrasos aleatorios: Utilice intervalos aleatorios (por ejemplo, 5-15 segundos) entre solicitudes para parecer más natural, mejorando la seguridad del raspado web. Esto evita patrones predecibles que suelen exhibir los bots.
- Patrones de clic realistas: Para navegadores sin interfaz gráfica, simule movimientos y clics del mouse con coordenadas y tiempos variados. Evite clics directos en elementos sin movimiento previo del mouse.
- Gestión de cookies: Mantenga y gestione cookies a través de sesiones para mantener el estado y reducir la sospecha. Los sitios web suelen usar cookies para rastrear sesiones de usuarios y identificar visitantes recurrentes.
- Encabezados
Referer: Establezca encabezadosRefereradecuados para parecer provenir de una fuente legítima (por ejemplo, un motor de búsqueda o una página anterior en el mismo sitio), agregando legitimidad a las solicitudes y seguridad del raspado web.
Estrategias avanzadas de proxies
Los proxies son cruciales para la seguridad del raspado web. Una mezcla de tipos de proxies mejora el éxito al distribuir las solicitudes y enmascarar tu dirección IP:
- Proxies residenciales: Estas IPs son asignadas por proveedores de servicios de Internet (ISPs) a usuarios residenciales. Son muy efectivos ya que parecen tráfico de usuarios legítimos, dificultando que los sistemas anti-bot los distingan de usuarios reales. Los proxies residenciales son cruciales para una seguridad del raspado web sólida, especialmente para objetivos altamente protegidos.
- Proxies móviles: Las IPs de operadores móviles son aún más difíciles de detectar debido a su naturaleza dinámica y asociación con dispositivos móviles reales. Ofrecen mayor anonimato y son excelentes para objetivos con medidas anti-bot estrictas.
- Proxies de centro de datos: Estos son más rápidos y económicos, pero más fácilmente detectables ya que provienen de centros de datos comerciales. Son adecuados para sitios web menos protegidos o fases iniciales de prueba donde el anonimato no es la principal preocupación.
Resumen comparativo: Tipos de proxies para la seguridad del raspado web
| Característica | Proxies de centro de datos | Proxies residenciales | Proxies móviles |
|---|---|---|---|
| Nivel de anonimato | Bajo a medio | Alto | Muy alto |
| Riesgo de detección | Alto | Bajo | Muy bajo |
| Velocidad | Alta | Media | Media |
| Costo | Bajo | Medio a alto | Alto |
| Caso de uso | Sitios menos protegidos | Sitios moderadamente protegidos | Sitios altamente protegidos |
| Fuente de IP | Centros de datos comerciales | ISPs | Operadores móviles |
Superar los desafíos de CAPTCHA con CapSolver
Las CAPTCHA son una defensa principal contra el raspado automatizado. La intervención manual es poco práctica para operaciones a gran escala, lo que hace que los servicios de resolución automatizada de CAPTCHA sean indispensables para la seguridad del raspado web.
CapSolver ofrece una solución sólida para diversos tipos de CAPTCHA, incluidas reCAPTCHA, Cloudflare Turnstile y desafíos basados en imágenes. Integrar CapSolver automatiza la resolución de CAPTCHA, asegurando la recolección ininterrumpida de datos. La infraestructura de CapSolver basada en inteligencia artificial reconoce y resuelve CAPTCHA complejos, permitiendo que su raspador continúe como si un usuario humano hubiera completado el desafío. Esto es valioso cuando la imitación del comportamiento humano tradicional es insuficiente. Por ejemplo, para reCAPTCHA v3, CapSolver proporciona un token para evitar la verificación basado en una evaluación de riesgo sofisticada, mejorando significativamente la seguridad y la eficiencia del raspado web.
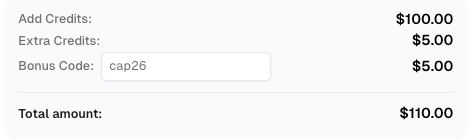
Use el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Los servicios de CapSolver se integran sin problemas en marcos de raspado existentes, proporcionando soluciones para:
- reCAPTCHA v2/v3: Resolver desafíos de reCAPTCHA de casilla y invisible generando tokens válidos.
- Cloudflare Turnstile: Resolver con precisión los acertijos de Cloudflare Turnstile, diseñados para ser privados y efectivos contra bots.
- CAPTCHAs ImageToText: Transcribir texto distorsionado de imágenes utilizando tecnología avanzada de reconocimiento óptico de caracteres (OCR).
Aprovechar estos servicios mejora la resistencia de las operaciones de raspado web frente a medidas anti-bot sofisticadas. Para detalles de integración, consulte la documentación oficial, como Cómo elegir una API de resolución de CAPTCHA? Guía del comprador 2026 y comparación.
Consideraciones legales y éticas
Entender el escenario legal y ético es fundamental para la seguridad del raspado web a largo plazo. Ignorar estos aspectos puede llevar a consecuencias graves. Según un informe de Zyte, el raspado web en sí no es inherentemente ilegal, pero su legalidad depende en gran medida de los datos que se raspen y de los métodos utilizados. Siempre priorice las consideraciones éticas para mantener una buena reputación y evitar conflictos legales.
Respetar robots.txt y los Términos de Servicio
robots.txt: Este archivo dirige a los rastreadores web sobre qué partes de un sitio web evitar. Siempre siga estas reglas. Es una guía ética sólida, y ignorarla puede violar la política del sitio web y comprometer la seguridad del raspado web. Respetarrobots.txtes un aspecto fundamental del raspado responsable.- Términos de Servicio (ToS): Los sitios web a menudo prohíben la recolección automatizada de datos en sus ToS. Violar estos términos puede llevar a la terminación de la cuenta, prohibiciones de IP y disputas legales. Siempre revise los ToS antes de iniciar cualquier actividad de raspado para garantizar la conformidad.
Privacidad de datos y cumplimiento
Al raspar datos personales, el cumplimiento con regulaciones como el RGPD (Reglamento General de Protección de Datos) y la CCPA (Ley de Protección al Consumidor de California) es crítico. Asegúrese de que los datos recopilados se manejen de manera responsable, anonimizados si es necesario, y utilizados solo para fines legítimos. La no conformidad puede resultar en multas significativas y consecuencias legales. Priorizar la privacidad de los datos es un componente clave de la seguridad del raspado web. Por ejemplo, la Asociación Internacional de Profesionales de la Privacidad (IAPP) destaca cómo las leyes europeas de protección de datos limitan significativamente el uso legal del raspado web, especialmente en cuanto a datos personales. Además, entender el cumplimiento con tanto el RGPD como la CCPA es esencial para los raspadores que operan a nivel mundial, ya que estas regulaciones imponen requisitos estrictos sobre la recolección y procesamiento de datos.
Conclusión
La seguridad del raspado web es un proceso continuo de adaptación. Al comprender los sistemas anti-bot, imitar el comportamiento humano, emplear estrategias avanzadas de proxies y aprovechar servicios de resolución automatizada de CAPTCHA como CapSolver, mejora la resiliencia de la recolección de datos. Siempre priorice el cumplimiento legal y ético, respetando robots.txt, los Términos de Servicio y la privacidad de los datos. Mantenerse informado sobre técnicas anti-bot y monitorear el rendimiento garantiza operaciones robustas y no detectadas. Este enfoque proactivo para la seguridad del raspado web permite obtener información valiosa mientras mantiene una estrategia de adquisición de datos responsable y sostenible.
Preguntas frecuentes
P1: ¿Es legal el raspado web?
La legalidad del raspado web es compleja, dependiendo de los datos que se raspen, los Términos de Servicio (ToS) del sitio web y las leyes de protección de datos (por ejemplo, RGPD, CCPA). Generalmente, raspar datos disponibles públicamente suele ser permisible, pero los datos protegidos por derechos de autor o personales sin consentimiento explícito pueden ser ilegales. Siempre es recomendable consultar a un abogado si no está seguro de la legalidad de sus actividades de raspado específicas.
P2: ¿Cómo puedo evitar que se bloquee mi IP durante el raspado web?
Para evitar que se bloquee su IP, implemente una estrategia que incluya rotación de IP con proxies diversos (residenciales, móviles), introduzca retrasos aleatorios entre las solicitudes para simular patrones de navegación humana y imite el comportamiento del navegador humano con encabezados adecuados de User-Agent y Referer. Monitorear continuamente sus registros de raspado en busca de actividad inusual o códigos de error (como 403 o 429) es crucial para ajustes proactivos y mantener la seguridad del raspado web.
P3: ¿Qué es la huella digital del navegador y cómo afecta al raspado web?
La huella digital del navegador recopila características únicas del navegador, como fuentes instaladas, complementos, resolución de pantalla, sistema operativo y configuración regional, para crear un identificador único para un usuario. Los sistemas anti-bot utilizan esto para detectar navegadores sin cabeza o scripts automatizados que presenten huellas digitales inconsistentes o no humanas. Los raspadores avanzados deben usar herramientas y técnicas para simular huellas digitales realistas y consistentes para evitar la detección.
P4: ¿Cómo funcionan los servicios de resolución de CAPTCHA como CapSolver?
CapSolver utiliza algoritmos avanzados de Inteligencia Artificial (IA) y aprendizaje automático para reconocer y resolver diversos tipos de CAPTCHA. Cuando su raspador se encuentra con un desafío de CAPTCHA, envía el desafío a la API de CapSolver. CapSolver procesa el desafío, genera una solución y la devuelve a su raspador. Este proceso evita la CAPTCHA para una extracción de datos ininterrumpida, mejorando significativamente la eficiencia y fiabilidad de sus operaciones de raspado web y mejorando la seguridad del raspado web.
P5: ¿Qué son los honeypots y cómo puedo evitarlos?
Los honeypots son enlaces o elementos invisibles integrados dentro de una página web diseñados para atrapar bots automatizados. Un usuario humano no vería o interactuaría con estos elementos, pero un bot podría hacerlo. Para evitar los honeypots, su raspador debe analizar las propiedades CSS de los enlaces (por ejemplo, display: none, visibility: hidden o color: #fff en un fondo blanco) y evitar seguir cualquier enlace oculto para el usuario humano. Este análisis cuidadoso es crítico para mantener la seguridad del raspado web y evitar la detección inmediata y el bloqueo.
Ver más
aws wafJul 23, 2026
Cómo resolver AWS WAF en LangChain con CapSolver
Construya un flujo de trabajo de AWS WAF autorizado con herramientas CapSolver, detección de respuestas, puertas de política, manejo de sesiones, reintentos y verificación.
AIJul 23, 2026
Cómo resolver Cloudflare Turnstile en agentes de LangGraph
Construye un flujo de trabajo de solucionador de Cloudflare Turnstile de LangGraph con CapSolver, manejo de sesiones de Playwright, puertas de política, reintentos, verificación y revisión.