Mengambil Data Web dengan Selenium dan Python | Menyelesaikan Captcha Saat Mengambil Data Web

Emma Foster
Machine Learning Engineer
Bayangkan Anda dapat dengan mudah mendapatkan semua data yang Anda butuhkan dari Internet tanpa harus secara manual menjelajahi web atau menyalin dan menempelkan. Itulah keindahan dari pengambilan data web. Baik Anda seorang analis data, peneliti pasar, atau pengembang, pengambilan data web membuka dunia baru yang penuh otomatisasi dalam pengumpulan data.
Di era yang didorong oleh data ini, informasi adalah kekuatan. Namun, mengekstrak informasi secara manual dari ratusan bahkan ribuan halaman web tidak hanya memakan waktu, tetapi juga rentan terhadap kesalahan. Untungnya, pengambilan data web menawarkan solusi yang efisien dan akurat yang memungkinkan Anda mengotomatisasi proses pengambilan data dari Internet, sehingga secara signifikan meningkatkan efisiensi dan kualitas data.
Daftar Isi
Apa itu Web Scraping?
Web scraping adalah teknik untuk mengekstrak informasi secara otomatis dari halaman web dengan menulis program. Teknologi ini memiliki berbagai aplikasi di berbagai bidang, termasuk analisis data, penelitian pasar, intelijen kompetitif, agregasi konten, dan lainnya. Dengan web scraping, Anda dapat mengumpulkan dan mengkonsolidasikan data dari banyak halaman web dalam waktu singkat, bukan bergantung pada operasi manual.
Proses web scraping biasanya mencakup langkah-langkah berikut:
- Kirim permintaan HTTP: Mengirim permintaan secara programatis ke situs web target untuk mendapatkan kode sumber HTML halaman web. Alat yang umum digunakan seperti perpustakaan requests Python dapat melakukannya dengan mudah.
- Parsing konten HTML: Setelah mendapatkan kode sumber HTML, perlu di-parse untuk mengekstrak data yang diperlukan. Perpustakaan parsing HTML seperti BeautifulSoup atau lxml dapat digunakan untuk memproses struktur HTML.
- Ekstraksi data: Berdasarkan struktur HTML yang di-parse, temukan dan ekstrak konten spesifik, seperti judul artikel, informasi harga, tautan gambar, dll. Metode umum termasuk menggunakan XPath atau selector CSS.
- Simpan data: Simpan data yang diekstrak ke media penyimpanan yang sesuai, seperti database, file CSV atau file JSON, untuk analisis dan pemrosesan selanjutnya.
Dan dengan menggunakan alat seperti Selenium, dapat mensimulasikan operasi browser pengguna, melewati beberapa mekanisme anti-crawler, sehingga menyelesaikan tugas web scraping lebih efisien.
Tukarkan Kode Bonus CapSolver
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAPN saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan bonus tambahan 5% pada setiap penukaran — tanpa batas.
Tukarkan sekarang di Dashboard CapSolver
.
Memulai dengan Selenium
Mari kita ambil ScrapingClub sebagai contoh dan gunakan selenium untuk menyelesaikan latihan pertama.
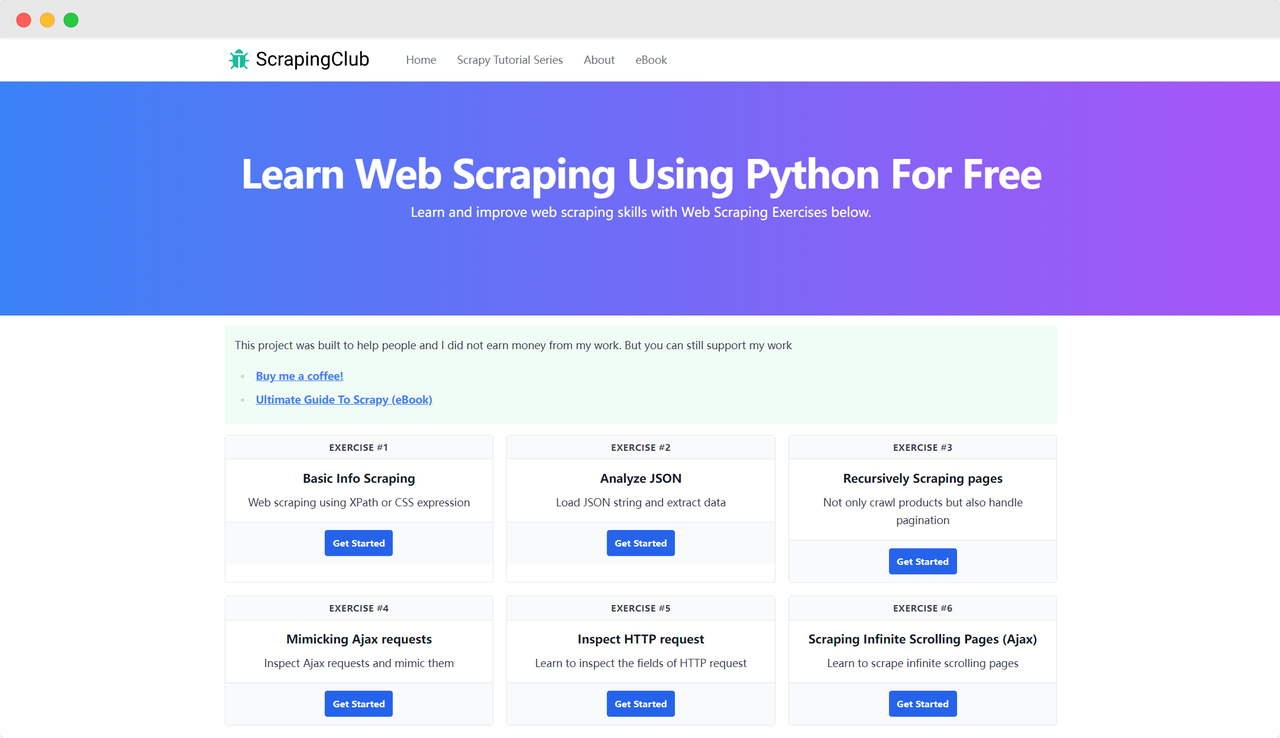
Persiapan
Pertama, Anda perlu memastikan bahwa Python terinstal di mesin lokal Anda. Anda dapat memeriksa versi Python dengan memasukkan perintah berikut di terminal Anda:
bash
python --versionPastikan versi Python lebih besar dari 3. Jika tidak terinstal atau versinya terlalu rendah, silakan unduh versi terbaru dari situs web Python resmi. Selanjutnya, Anda perlu menginstal perpustakaan selenium dengan perintah berikut:
bash
pip install seleniumImpor Perpustakaan
python
from selenium import webdriverMengakses Halaman
Menggunakan Selenium untuk menggerakkan Google Chrome mengakses halaman tidak terlalu rumit. Setelah menginisialisasi objek Chrome Options, Anda dapat menggunakan metode get() untuk mengakses halaman target:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Parameter Startup
Chrome Options dapat menambahkan banyak parameter startup yang membantu meningkatkan efisiensi pengambilan data. Anda dapat melihat daftar lengkap parameter di situs web resmi: Daftar Switch Baris Perintah Chromium. Beberapa parameter yang umum digunakan tercantum dalam tabel berikut:
| Parameter | Tujuan |
|---|---|
| --user-agent="" | Atur User-Agent dalam header permintaan |
| --window-size=xxx,xxx | Atur resolusi browser |
| --start-maximized | Jalankan dengan resolusi yang diperbesar |
| --headless | Jalankan dalam mode headless |
| --incognito | Jalankan dalam mode incognito |
| --disable-gpu | Nonaktifkan akselerasi GPU hardware |
Contoh: Berjalan dalam Mode Headless
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Mengidentifikasi Elemen Halaman
Langkah yang diperlukan dalam mengambil data adalah menemukan elemen HTML yang sesuai di DOM. Selenium menyediakan dua metode utama untuk mengidentifikasi elemen di halaman:
find_element: Menemukan satu elemen yang memenuhi kriteria.find_elements: Menemukan semua elemen yang memenuhi kriteria.
Kedua metode ini mendukung delapan cara berbeda untuk mengidentifikasi elemen HTML:
| Metode | Makna | Contoh HTML | Contoh Selenium |
|---|---|---|---|
| By.ID | Identifikasi berdasarkan ID elemen | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | Identifikasi berdasarkan nama elemen | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | Identifikasi berdasarkan XPath | <p><code>My code</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | Identifikasi tautan hyperlink berdasarkan teks | <a href="continue.html">Continue</a> |
driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | Identifikasi tautan hyperlink berdasarkan teks sebagian | <a href="continue.html">Continue</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | Identifikasi berdasarkan nama tag | <h1>Welcome</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | Identifikasi berdasarkan nama kelas | <p class="content">Welcome</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | Identifikasi berdasarkan selector CSS | <p class="content">Welcome</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
Mari kembali ke halaman ScrapingClub dan tulis kode berikut untuk menemukan elemen tombol "Get Started" untuk latihan satu:
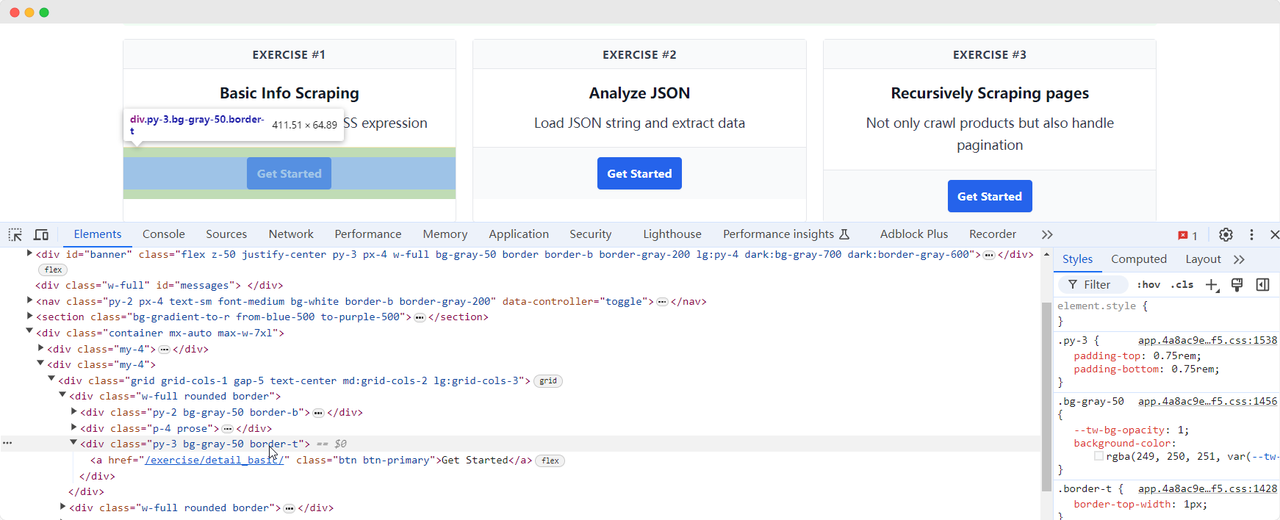
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()Interaksi Elemen
Setelah kita menemukan elemen tombol "Get Started", kita perlu mengklik tombol tersebut untuk masuk ke halaman berikutnya. Ini melibatkan interaksi elemen. Selenium menyediakan beberapa metode untuk mensimulasikan tindakan:
click(): Klik elemen;clear(): Hapus konten elemen;send_keys(*value: str): Mensimulasikan input keyboard;submit(): Kirim formulir;screenshot(filename): Simpan screenshot halaman.
Untuk interaksi lebih lanjut, merujuk ke dokumentasi resmi: WebDriver API. Mari lanjutkan memperbaiki kode latihan ScrapingClub dengan menambahkan interaksi klik:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()Ekstraksi Data
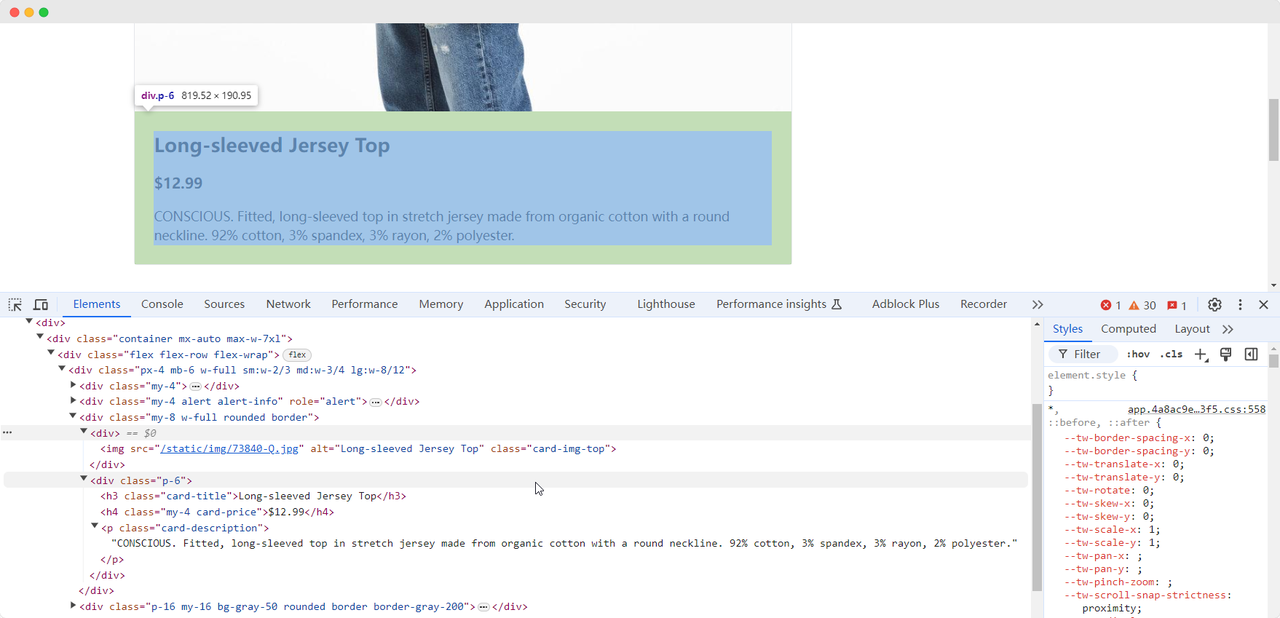
Ketika kita tiba di halaman latihan pertama, kita perlu mengumpulkan informasi gambar, nama, harga, dan deskripsi produk. Kita dapat menggunakan metode berbeda untuk menemukan elemen-elemen ini dan mengekstraknya:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nama produk: {product_name}')
print(f'Gambar produk: {product_image}')
print(f'Harga produk: {product_price}')
print(f'Deskripsi produk: {product_description}')
driver.quit()Kode ini akan menghasilkan konten berikut:
Nama produk: Long-sleeved Jersey Top
Gambar produk: https://scrapingclub.com/static/img/73840-Q.jpg
Harga produk: $12.99
Deskripsi produk: CONSCIOUS. Atasan berlengan panjang dengan bahan jersey stretch dari kapas organik dengan kerah bulat. 92% kapas, 3% spandex, 3% rayon, 2% poliester.Menunggu Elemen Dimuat
Terkadang, karena masalah jaringan atau alasan lain, elemen mungkin belum dimuat ketika Selenium selesai berjalan, yang dapat menyebabkan beberapa kegagalan pengumpulan data. Untuk menyelesaikan masalah ini, kita dapat mengatur agar menunggu hingga elemen tertentu dimuat sepenuhnya sebelum melanjutkan ke ekstraksi data. Berikut adalah contoh kode:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# menunggu hingga elemen gambar produk dimuat sepenuhnya
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nama produk: {product_name}')
print(f'Gambar produk: {product_image}')
print(f'Harga produk: {product_price}')
print(f'Deskripsi produk: {product_description}')
driver.quit()Mengatasi Perlindungan Anti-Scraping
Latihan ScrapingClub mudah diselesaikan. Namun, dalam skenario pengumpulan data nyata, mendapatkan data tidak semudah itu karena beberapa situs web menggunakan teknik anti-scraping yang mungkin mendeteksi skrip Anda sebagai bot dan memblokir pengumpulan. Situasi yang paling umum adalah tantangan captcha
Menyelesaikan tantangan captcha ini memerlukan pengalaman luas dalam machine learning, reverse engineering, dan countermeasures browser fingerprint, yang bisa memakan banyak waktu. Untungnya, sekarang Anda tidak perlu melakukan semua pekerjaan ini sendiri. CapSolver menyediakan solusi lengkap untuk membantu Anda melewati semua tantangan dengan mudah. CapSolver menawarkan ekstensi browser yang dapat secara otomatis menyelesaikan tantangan captcha saat menggunakan Selenium untuk mengumpulkan data. Selain itu, mereka menyediakan metode API untuk menyelesaikan captcha dan mendapatkan token, semua dapat diselesaikan dalam beberapa detik. Merujuk ke Dokumentasi CapSolver untuk informasi lebih lanjut.
Kesimpulan
Dari mengekstrak detail produk hingga menavigasi melalui perlindungan anti-scraping yang kompleks, pengambilan data web dengan Selenium membuka pintu menuju dunia yang luas dari pengumpulan data otomatis. Saat kita menjelajahi lingkungan web yang terus berkembang, alat seperti CapSolver membuka jalan untuk pengambilan data yang lebih mulus, membuat tantangan yang dulu sulit menjadi hal yang sudah lewat. Jadi, baik Anda seorang penggemar data atau pengembang berpengalaman, memanfaatkan teknologi ini tidak hanya meningkatkan efisiensi tetapi juga membuka dunia di mana wawasan berbasis data hanya beberapa kali mengklik.
FAQ
1. Apa yang digunakan untuk web scraping?
Web scraping digunakan untuk mengekstrak informasi secara otomatis dari halaman web. Ini memungkinkan pengembang, analis, dan bisnis untuk mengumpulkan data produk, harga, artikel, gambar, ulasan, dan informasi online lainnya secara massal tanpa salinan manual, secara signifikan meningkatkan efisiensi dan akurasi data.
2. Mengapa menggunakan Selenium untuk web scraping daripada requests atau BeautifulSoup?
Requests dan BeautifulSoup bekerja dengan baik untuk halaman web statis, tetapi banyak situs web modern menggunakan JavaScript untuk memuat konten. Selenium meniru browser nyata, memungkinkan Anda mengambil data dari halaman dinamis, klik tombol, menggulung, berinteraksi dengan elemen, dan melewati pengukuran anti-scraping sederhana—membuatnya ideal untuk skenario kompleks.
3. Dapatkah Selenium mengambil data dari situs web yang memerlukan login atau tindakan pengguna?
Ya. Selenium dapat melakukan interaksi seperti klik tombol, ketik teks, navigasi halaman, dan mengelola kuki atau sesi, membuatnya cocok untuk mengambil data dari halaman di balik formulir login atau alur kerja pengguna.
4. Bagaimana cara menghadapi CAPTCHA saat mengambil data?
CAPTCHA adalah mekanisme anti-bot yang umum yang dapat menghentikan skrip Selenium. Alih-alih menyelesaikannya secara manual, Anda dapat mengintegrasikan solusi seperti CapSolver, yang menyediakan penyelesaian CAPTCHA otomatis melalui API atau ekstensi browser untuk memastikan proses pengambilan data tidak terganggu.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.
Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

