Terbaik Web Scraping vs Pilihan API untuk Tim Otomasi

Emma Foster
Machine Learning Engineer
TL;DR
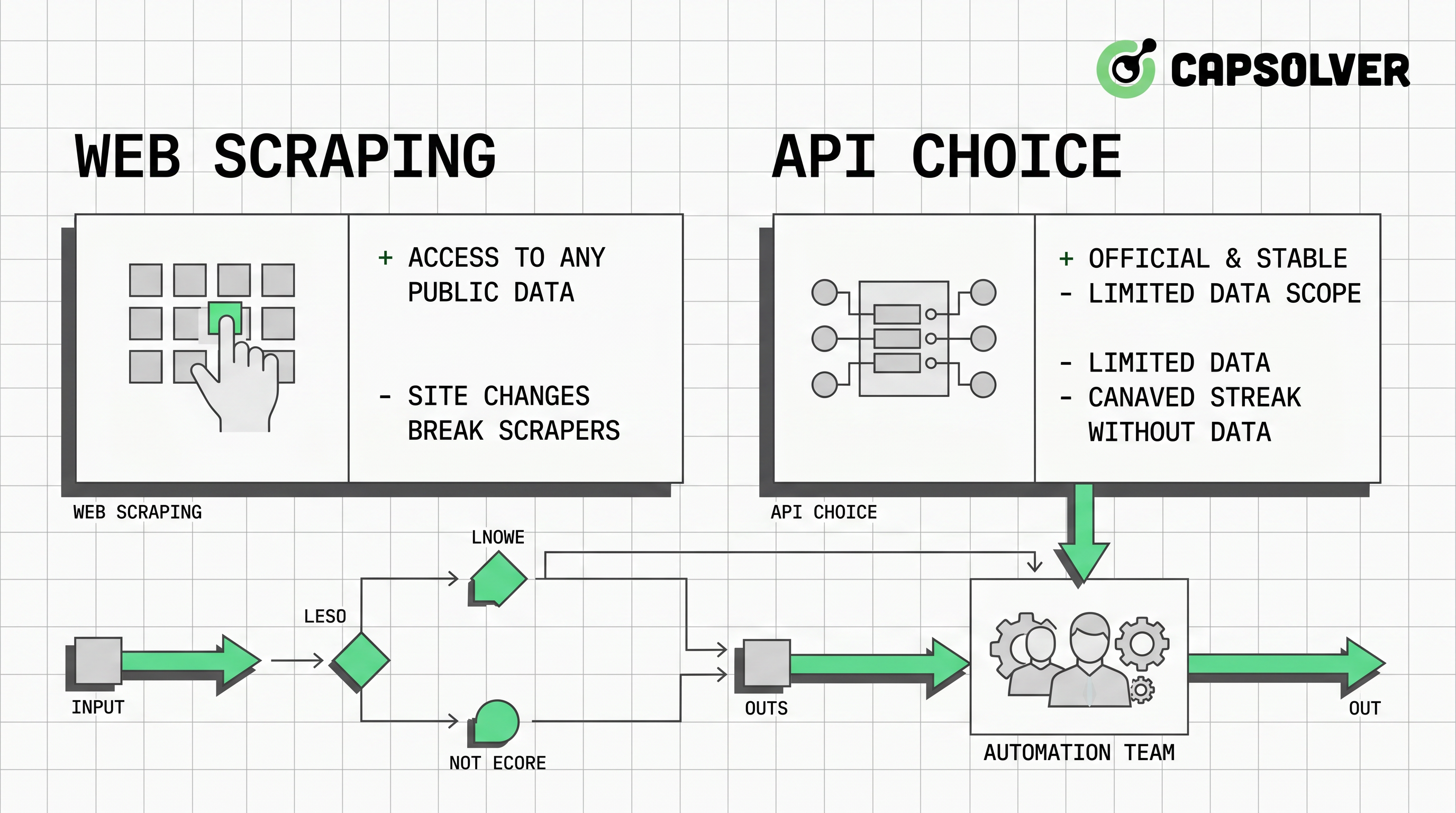
- Keputusan terbaik antara web scraping vs API sebaiknya dimulai dengan hak data, ketersediaan sumber, persyaratan keandalan, dan biaya pemeliharaan.
- API biasanya lebih baik untuk sistem produksi yang diatur karena skema, batas laju, otentikasi, dan versi lebih mudah didokumentasikan.
- Web scraping berguna ketika data publik yang diizinkan tidak memiliki API yang sesuai, tetapi memerlukan peninjauan robots.txt, kontrol laju, pemantauan perubahan halaman, dan pemeriksaan kepatuhan.
- Otomatisasi browser menambah nilai untuk halaman dinamis, dan CapSolver dapat membantu alur kerja yang disetujui menangani CAPTCHA atau peristiwa validasi lalu lintas ketika muncul.
- Arsitektur yang paling tahan lama menggunakan API terlebih dahulu, web scraping kedua, otomatisasi browser hanya ketika diperlukan, dan penyelesaian CAPTCHA sebagai jalur pengecualian yang dikendalikan.
Pendahuluan
Pemilihan terbaik antara web scraping vs API jarang berkaitan dengan metode mana yang lebih kuat. Mereka berkaitan dengan metode mana yang lebih andal, diizinkan, dapat dipelihara, dan dapat diaudit untuk data yang dibutuhkan tim Anda. API biasanya datang terlebih dahulu ketika menyediakan bidang yang diperlukan, segar, dan ketentuan yang sesuai. Web scraping menjadi berguna ketika halaman publik yang diizinkan adalah satu-satunya sumber yang praktis atau ketika tim perlu memantau perubahan di lapisan tampilan. Jika alur scraping atau otomatisasi browser yang disetujui menghadapi tantangan CAPTCHA, panduan penyelesaian CAPTCHA saat scraping dari CapSolver dapat memberikan jalur penyelesaian yang terdokumentasi yang sesuai dengan proses otomatisasi yang lebih luas.
Pendekatan API terlebih dahulu seharusnya menjadi keputusan default
API biasanya menjadi pilihan default karena menyajikan kontrak yang didukung penyedia. API yang dirancang dengan baik memberikan bidang yang dapat diprediksi, otentikasi, batas laju, kode kesalahan, dan versi kepada tim. Sifat-sifat ini membuat ulasan insinyur lebih mudah dan mengurangi kebutuhan untuk parsing yang rapuh. API juga menyederhanakan garis data karena setiap catatan dapat dikaitkan dengan endpoint, timestamp, ID permintaan, atau skema yang terdokumentasi.
Panduan dan referensi API REST menjelaskan ide desain API umum seperti sumber daya, metode, dan representasi. Dokumentasi batas laju API REST GitHub menunjukkan mengapa batas laju bukanlah penghalang tetapi kontrak operasional. Dalam banyak program otomatisasi, API resmi yang lebih lambat lebih baik daripada scraper yang lebih cepat karena API lebih mudah dibela dalam audit dan lebih mudah dipelihara ketika konsumen data tumbuh.
| Faktor keputusan | Keunggulan API | Keunggulan web scraping |
|---|---|---|
| Kontrak data | Skema yang stabil dan kesalahan yang terdokumentasi | Dapat mengumpulkan bidang yang terlihat yang tidak diekspos oleh endpoint |
| Pemeliharaan | Versi dan saluran dukungan | Bekerja ketika tidak ada API yang sesuai |
| Segar | Polling yang dapat diprediksi dan batas laju | Dapat mencerminkan pembaruan halaman secara cepat |
| Halaman dinamis | Overhead browser yang lebih sedikit | Otomatisasi browser dapat memeriksa keadaan yang dirender |
| Peristiwa tantangan | Biasanya dihindari | Mungkin memerlukan alur kerja penyelesaian CAPTCHA yang dikendalikan |
Kuncinya bukan menolak scraping. Kuncinya adalah membuktikan bahwa scraping diperlukan sebelum menambah kompleksitas operasional.
Ketika web scraping lebih cocok
Web scraping lebih cocok ketika data bersifat publik, diizinkan, tidak tersedia melalui API yang sesuai, dan bernilai cukup untuk membenarkan pemantauan. Contoh umum termasuk halaman harga publik, halaman ketersediaan produk, daftar pekerjaan publik, direktori publik, dan pemantauan perubahan situs web. Bahkan demikian, tim harus mendokumentasikan bidang data, halaman sumber, frekuensi penggulungan, aturan pengecualian, dan pemilik bisnis yang bertanggung jawab atas alur kerja.
Protokol Pengecualian Robot RFC 9309 mendefinisikan cara situs web dapat berkomunikasi aturan penggulungan kepada klien otomatis. Referensi URL MDN berguna untuk normalisasi URL, yang merupakan kebutuhan dasar untuk deduplikasi dan batas penggulungan. Referensi ini mendukung aturan praktis: web scraping harus diperlakukan sebagai sistem insinyur dengan izin dan batas, bukan sebagai skrip informal.
Web scraping juga memanfaatkan desain berlapis. Halaman statis sering kali dapat ditangani dengan permintaan HTTP dan parser. Halaman yang berat JavaScript mungkin memerlukan otomatisasi browser. Halaman dengan validasi lalu lintas mungkin memerlukan kebijakan penanganan tantangan yang terdokumentasi. Panduan integrasi Playwright dari CapSolver berguna ketika lapisan otomatisasi membutuhkan ekstraksi dan penanganan tantangan yang dikendalikan.
Di mana penyelesaian CAPTCHA seharusnya dalam keputusan
Penyelesaian CAPTCHA seharusnya berada di akhir pohon keputusan terbaik antara web scraping vs API. Jika API ada dan memenuhi kebutuhan, gunakan itu. Jika halaman publik dapat dikumpulkan melalui ekstraksi statis yang diizinkan, gunakan itu. Jika otomatisasi browser diperlukan, tambahkan kontrol rendering dan interaksi. Hanya setelah pilihan-pilihan ini, tim harus memutuskan cara menangani tantangan CAPTCHA atau validasi lalu lintas yang didukung.
Glosari reCAPTCHA dan panduan terminologi CAPTCHA dari CapSolver membantu tim mengidentifikasi keluarga tantangan umum sebelum memilih jalur penyelesaian. Keputusan harus mencakup cakupan persetujuan, domain yang didukung, batas ulang coba, pencatatan, kebijakan proxy, dan pemeriksaan keberhasilan tingkat halaman. Penyelesaian tantangan yang berhasil tidak cukup; alur kerja harus memastikan tugas yang disetujui selesai dengan benar.
Kode Bonus untuk pilot otomatisasi data yang disetujui
Tukarkan Kode Bonus CapSolver
Meningkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap penyetoran — tanpa batas.
Tukarkan sekarang di Dashboard CapSolver
Pola arsitektur untuk tim otomatisasi
Arsitektur yang kuat memisahkan metode akses, eksekusi, validasi, dan tata kelola. Metode akses mungkin merupakan API, scraper statis, skrip otomatisasi browser, atau alur kerja hibrid. Eksekusi harus menerapkan batas laju, ulang coba, dan kondisi berhenti yang aman. Validasi harus membandingkan jumlah catatan, bidang yang diperlukan, timestamp sumber, dan perubahan skema. Tata kelola harus mencatat siapa yang menyetujui sumber, data apa yang diizinkan, dan kapan alur kerja harus ditinjau kembali.
Untuk alur kerja yang berat browser, dokumentasi Playwright memberikan titik awal praktis untuk rendering dan interaksi halaman yang dikendalikan. Untuk alur kerja yang berat crawler, dokumentasi Scrapy menjelaskan spider, item, dan pipa. Untuk alur kerja yang berat tantangan dan disetujui, panduan ekstensi browser dari CapSolver dapat membantu insinyur mendiagnosis perilaku halaman nyata sebelum mereka merancang jalur API terlebih dahulu yang dapat diulang.
| Pola arsitektur | Gunakan ketika | Tambahkan kontrol ini |
|---|---|---|
| Hanya API | Bidang yang diperlukan tersedia dan ketentuan memungkinkan penggunaan | Pemantauan endpoint dan penanganan batas laju |
| Web scraping statis | Halaman publik stabil dan diizinkan | Peninjauan robots.txt dan uji selektor |
| Otomatisasi browser | Rendering atau interaksi diperlukan | Anggaran waktu tunggu dan validasi keadaan halaman |
| Hibrid API plus scraping | API mencakup sebagian besar bidang tetapi halaman menambah konteks | Aturan sumber kebenaran dan deduplikasi |
| Web scraping plus CapSolver | Halaman yang disetujui menampilkan tantangan CAPTCHA | Tiket persetujuan, log yang dirahasiakan, dan batas ulang coba |
Struktur ini membuat keputusan terbaik antara web scraping vs API transparan. Ini juga mengurangi risiko tim menambahkan otomatisasi browser atau penyelesaian CAPTCHA sebelum mereka membuktikan bahwa metode yang lebih sederhana tidak dapat memenuhi kebutuhan bisnis.
Daftar Periksa Penggunaan yang Bertanggung Jawab
Program otomatisasi yang bertanggung jawab dimulai dengan ulasan sumber. Pastikan data bersifat publik atau diizinkan, tujuan pengumpulan sah, dan data pribadi sensitif atau terbatas di luar cakupan kecuali ada dasar hukum dan kontrol keamanan yang ada. Kemudian tinjau robots.txt, ketentuan situs, dokumentasi API, dan kewajiban kontraktual. Akhirnya, uji dengan volume rendah dan hentikan alur kerja ketika dinding login yang tidak terduga, perubahan izin, lonjakan tantangan, atau pergeseran skema muncul.
Proyek Ancaman Otomatis OWASP adalah pengingat yang berguna bahwa teknik otomatisasi yang sama dapat disalahgunakan. Standar internal Anda harus memerlukan izin, laju permintaan yang proporsional, identifikasi yang jelas di tempat yang tepat, dan tinjauan manusia ketika alur kerja berubah. CapSolver hanya boleh digunakan untuk target yang dimiliki, disiapkan, disetujui klien, atau lainnya yang diizinkan di mana penyelesaian tantangan merupakan bagian dari proses otomatisasi yang sah.
Kesimpulan
Keputusan terbaik antara web scraping vs API harus dibuat dengan hierarki sederhana: gunakan API ketika memenuhi kebutuhan, gunakan web scraping statis yang diizinkan ketika tidak, gunakan otomatisasi browser ketika rendering diperlukan, dan tambahkan penyelesaian CAPTCHA hanya sebagai jalur pengecualian yang terdokumentasi. Untuk tim yang membutuhkan penyelesaian tantangan yang andal dalam otomatisasi yang disetujui, panduan hukum web scraping dari CapSolver dapat membantu menempatkan penyelesaian di dalam alur kerja yang diatur bersama API, crawler, otomatisasi browser, pemantauan, dan tinjauan kepatuhan.
FAQ
Apa aturan terbaik antara web scraping vs API?
Aturan terbaik adalah API terlebih dahulu, kemudian web scraping. Gunakan API ketika menyediakan data di bawah ketentuan yang dapat diterima, dan gunakan web scraping hanya ketika halaman yang diizinkan adalah sumber yang praktis.
Kapan web scraping lebih baik daripada API?
Web scraping lebih baik ketika data halaman publik yang diizinkan tidak tersedia melalui API yang sesuai, atau ketika tampilan halaman itu sendiri adalah data yang perlu dipantau oleh tim Anda.
Kapan otomatisasi browser harus ditambahkan?
Tambahkan otomatisasi browser hanya ketika ekstraksi HTTP statis tidak dapat menangkap konten yang dirender, interaksi pengguna, atau data setelah muat yang diperlukan untuk alur kerja yang disetujui.
Bagaimana CapSolver cocok dalam alur kerja web scraping vs API?
CapSolver cocok ketika alur kerja web scraping atau otomatisasi browser yang disetujui menghadapi tantangan CAPTCHA atau validasi lalu lintas yang didukung dan membutuhkan jalur penyelesaian yang terdokumentasi.
Apa yang harus diperiksa tim sebelum scraping?
Tim harus memeriksa izin, robots.txt, ketentuan, sensitivitas data, laju permintaan, dan aturan pemantauan. Mereka juga dapat meninjau FAQ web scraping dari CapSolver ketika penyelesaian tantangan merupakan bagian dari rencana yang disetujui.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.
Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

