Alternatif AI Scraper untuk Otomatisasi Data Web yang Andal

Emma Foster
Machine Learning Engineer
TL;DR
- Alternatif scraper AI sebaiknya dibandingkan berdasarkan akurasi ekstraksi, kontrol browser, cakupan API, kontrol kepatuhan, dan penanganan tantangan, bukan hanya berdasarkan antarmuka saja.
- Workflow terkuat sering kali menggabungkan lapisan ekstraksi AI dengan crawler deterministik, API resmi, pemantauan, dan jalur penyelesaian CAPTCHA yang dikendalikan untuk target yang disetujui.
- Otomatisasi browser berguna untuk halaman dinamis, tetapi tim perlu batas kecepatan, ulasan robots.txt, pemeriksaan izin, dan kondisi berhenti yang jelas sebelum mengumpulkan data.
- Tantangan CAPTCHA adalah pemeriksaan keandalan dalam beberapa alur kerja pengambilan data yang diizinkan, dan CapSolver dapat membantu tim menanganinya melalui API yang terdokumentasi dan jalur ekstensi browser.
- Tim sebaiknya memilih alat yang mempertahankan log audit, mengurangi pekerjaan pemeliharaan, dan membuat penggunaan yang bertanggung jawab lebih mudah bagi insinyur dan operator.
Pengantar
Alternatif scraper AI tidak lagi hanya alat tanpa kode visual. Mereka kini mencakup agen browser, API ekstraksi, kerangka kerja crawler, dan alur kerja hibrid yang menggunakan pembelajaran mesin hanya di tempat yang menambah nilai. Pilihan terbaik adalah yang mengumpulkan data publik yang diizinkan secara akurat, mendokumentasikan bagaimana alur kerja berperilaku, dan menangani peristiwa validasi lalu lintas secara bertanggung jawab. Ketika otomatisasi yang disetujui mencapai CAPTCHA atau tantangan serupa, panduan Penyelesaian CAPTCHA saat mengambil data dari CapSolver dapat membantu tim menentukan jalur pengecualian yang dikendalikan daripada menganggap penyelesaian sebagai strategi utama. Panduan ini membandingkan opsi AI-first, API-first, browser-first, dan hibrid agar tim dapat membangun otomatisasi data web yang andal tanpa mengulang pola pengambilan data yang rapuh.
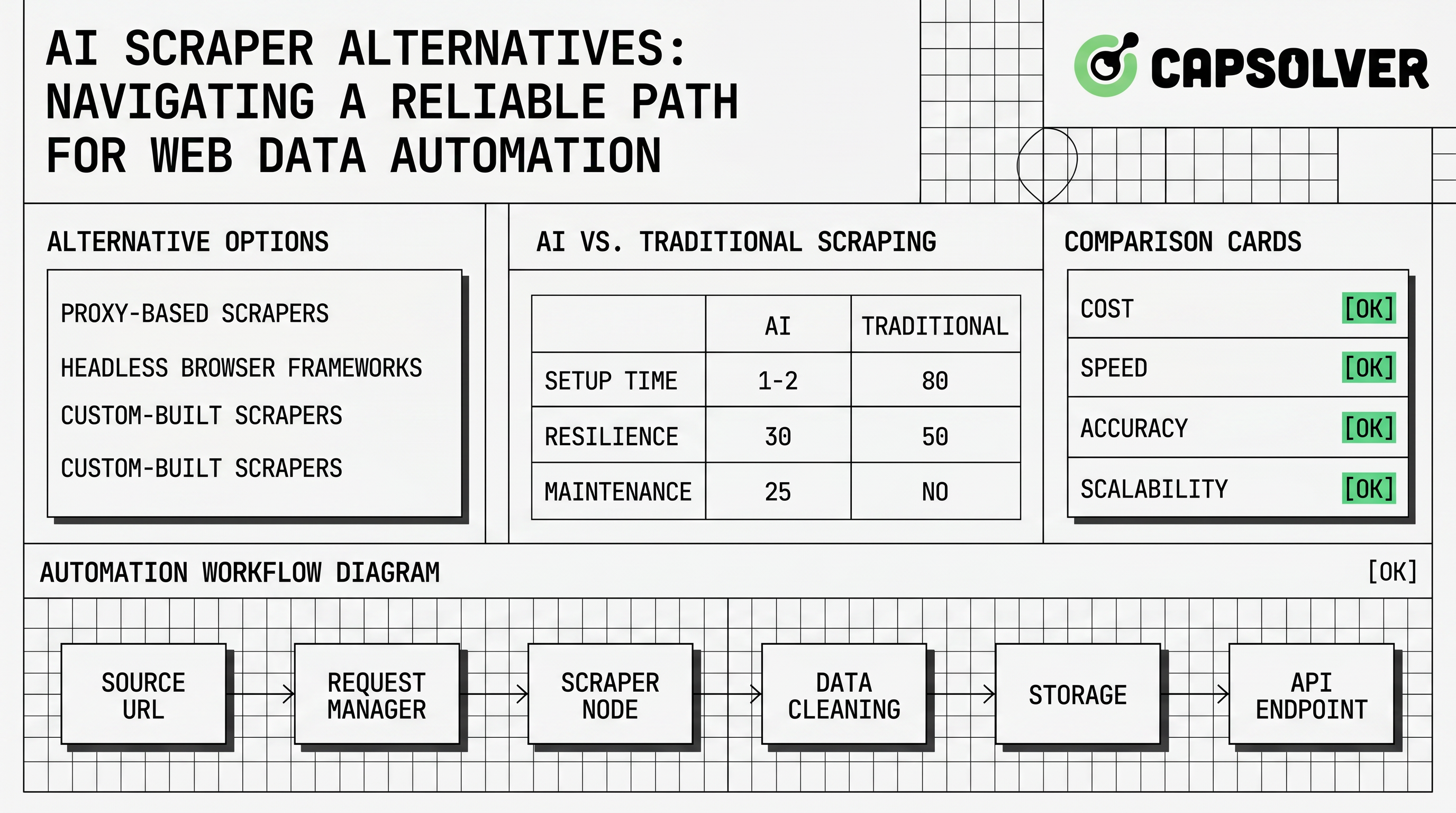
Apa yang Dianggap sebagai Alternatif Scraper AI
Alternatif scraper AI adalah alat atau arsitektur apa pun yang membantu tim mengumpulkan data web yang terstruktur tanpa bergantung pada selektor yang rapuh dan satu kali. Beberapa alat menggunakan model bahasa untuk mengidentifikasi bidang dari halaman. Lainnya menyediakan rendering yang dikelola, pengambilan data yang dijadwalkan, routing proxy, atau API ekstraksi yang siap pakai. Kerangka kerja tradisional tetap relevan karena kode deterministik lebih mudah diaudit, diuji, dan dipelihara ketika struktur situs target stabil.
Pasaran luas karena halaman web bervariasi. Katalog produk, papan pekerjaan, daftar perjalanan, dan direktori publik semua mengekspos markup, paginasi, pemuatan lambat, dan perilaku sesi yang berbeda. Ringkasan IBM tentang AI scraping menggambarkan AI scraping sebagai penggunaan AI untuk otomatisasi ekstraksi data situs web. Dokumentasi Scrapy menunjukkan ujung lain spektrum: kerangka kerja crawler yang dapat diprogram untuk ekstraksi terstruktur. Tim serius biasanya membutuhkan kedua konsep tersebut, karena AI dapat mengurangi pekerjaan pemetaan sementara kode deterministik menjaga produksi tetap terprediksi.
| Jenis Alternatif | Cocok untuk | Keuntungan Utama | Risiko yang Perlu Dikelola |
|---|---|---|---|
| Alat ekstraksi AI | Tata letak yang berubah dan halaman semi-terstruktur | Pemetaan bidang yang lebih cepat dan usaha pemasangan yang lebih rendah | Perbedaan output dan auditabilitas yang lebih lemah |
| Otomatisasi browser | Aplikasi dinamis dan halaman yang berat JavaScript | Eksekusi halaman nyata dan dukungan interaksi | Biaya lebih tinggi, kegagalan waktu, dan peristiwa tantangan |
| API pengambilan data | Rendering yang dikelola dan kesederhanaan operasional | Lebih sedikit pekerjaan infrastruktur | Ketergantungan pada vendor dan kontrol alur kerja yang lebih sedikit |
| Kerangka kerja crawler | Halaman stabil dan pipa yang dapat diulang | Pengujian yang kuat dan kontrol versi | Lebih banyak pekerjaan insinyur di awal |
| Stack hibrid | Tim produksi dengan target yang bervariasi | Keseimbangan antara fleksibilitas dan tata kelola | Membutuhkan kepemilikan dan dokumentasi yang jelas |
Alternatif scraper AI sebaiknya dipilih pada tingkat alur kerja. Alat yang terlihat menarik dalam demo masih bisa gagal jika tidak dapat mencatat persetujuan, menghormati aturan situs, mengulang dengan aman, atau berhenti ketika halaman berubah.
Kriteria Evaluasi untuk Alternatif Scraper AI
Kriteria pertama adalah akurasi data. Scraper modern seharusnya mengembalikan bidang yang konsisten, mempertahankan URL sumber, dan membuat ketidakpastian terlihat. Untuk ekstraksi berbasis AI, ini berarti mengambil sampel output, membandingkannya dengan catatan yang telah direview manusia, dan memantau bidang yang diimajinasikan. Untuk crawler deterministik, ini berarti pengujian unit, pemantauan selektor, dan penanganan yang jelas untuk halaman kosong atau berubah.
Kriteria kedua adalah akses yang bertanggung jawab. Tim sebaiknya meninjau robots.txt, syarat, ketersediaan API, batas kecepatan, dan izin kontraktual sebelum otomatisasi dimulai. Protokol Penyaring Robot RFC 9309 mendefinisikan robots.txt sebagai protokol untuk klien otomatis untuk mengidentifikasi aturan akses, sementara referensi URL MDN berguna ketika tim menyamakan URL kanonik dan menghilangkan catatan duplikat. Kemampuan teknis tidak menciptakan izin untuk mengumpulkan data pribadi, sensitif, terbatas, atau tidak sah.
Kriteria ketiga adalah penanganan tantangan. Beberapa target yang disetujui menggunakan CAPTCHA, Cloudflare Turnstile, atau sistem validasi lalu lintas lainnya. Dalam kasus tersebut, penyelesaian CAPTCHA harus diperlakukan sebagai jalur pengecualian yang terdokumentasi dengan persetujuan, batas kecepatan, log yang dirahasiakan, dan validasi hasil. Panduan Glosari CAPTCHA dari CapSolver membantu tim menyelaraskan terminologi sebelum mereka merancang alur kerja.
Di mana Penyelesaian CAPTCHA Cocok dalam Otomatisasi Data Web
Penyelesaian CAPTCHA bukan pusat dari arsitektur scraper AI, tetapi bisa menjadi lapisan keandalan yang diperlukan untuk otomatisasi yang diizinkan. Urutan yang benar sederhana. Pertama, utamakan API resmi atau aliran data ketika tersedia. Kedua, gunakan ekstraksi HTTP ringan ketika halaman statis dan diizinkan. Ketiga, gunakan otomatisasi browser hanya ketika rendering atau interaksi diperlukan. Terakhir, tambahkan jalur penanganan tantangan yang dikendalikan hanya ketika alur kerja disetujui dan halaman menampilkan langkah validasi.
Oleh karena itu, CapSolver paling baik diperkenalkan sebagai komponen alur kerja. Panduan FAQ CapSolver tentang pengambilan data memberikan konteks untuk alur kerja ekstraksi, sementara panduan integrasi CapSolver dengan Playwright menunjukkan bagaimana penanganan tantangan dapat terhubung ke otomatisasi browser. Tujuannya bukan untuk memaksa setiap scraper melalui layanan penyelesaian tantangan. Tujuannya adalah membuat jalur pengecualian konsisten, dapat diaudit, dan lebih mudah diuji.
Kode Bonus untuk Pengujian Otomatisasi yang Disetujui
Klaim Kode Bonus CapSolver Anda
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap penyetoran — tanpa batas.
Klaim sekarang di Dasbor CapSolver Anda
Arsitektur Praktis untuk Alternatif Scraper AI
Arsitektur yang andal memisahkan pencarian, ekstraksi, validasi, dan penyimpanan. Pencarian mengidentifikasi URL yang diizinkan dan aturan penjadwalan. Ekstraksi menggunakan metode dengan kompleksitas terendah yang bekerja, seperti panggilan API, parser HTTP, otomatisasi browser, atau prompt ekstraksi AI. Validasi memeriksa kelengkapan skema, catatan duplikat, timestamp, dan bukti sumber. Penyimpanan menyimpan snapshot mentah atau ID jejak ketika tim kepatuhan perlu meninjau proses pengumpulan.
Untuk halaman dinamis, alat browser seperti dokumentasi Playwright menyediakan rendering dan interaksi yang dikendalikan. Untuk pipa crawler, kerangka kerja seperti Scrapy menyediakan penjadwalan, pipa item, dan middleware. Untuk peristiwa tantangan, tim dapat merujuk panduan ekstensi browser CapSolver saat memecahkan masalah dan kemudian memindahkan alur kerja yang stabil ke integrasi API-first. Ini menjaga diagnosis manusia terpisah dari otomatisasi produksi yang dapat diulang.
| Lapisan alur kerja | Kontrol yang direkomendasikan | Mengapa penting |
|---|---|---|
| Ulasan izin | Domain yang disetujui dan kelas data yang diizinkan | Mencegah pengumpulan di luar cakupan yang ditentukan |
| Ekstraksi | API terlebih dahulu, lalu HTTP, lalu browser, lalu parsing yang didukung AI | Mengurangi biaya dan menghindari kompleksitas yang tidak perlu |
| Penanganan tantangan | Jalur CapSolver yang terdokumentasi untuk target yang disetujui | Menjaga peristiwa CAPTCHA dari menjadi perbaikan manual yang tidak terstruktur |
| Pemantauan | Pemeriksaan skema dan pemberitahuan perubahan halaman | Mendeteksi pergeseran sebelum data buruk mencapai pengguna |
| Log | ID tugas yang dirahasiakan dan bukti sumber | Mendukung audit tanpa mengungkap nilai sensitif |
Arsitektur ini juga membantu tim memutuskan kapan tidak menggunakan AI. Jika halaman memiliki markup yang stabil dan model paginasi yang dapat diprediksi, kode deterministik mungkin lebih andal daripada ekstraktor yang didorong model. Jika sumber menawarkan API yang terdokumentasi, API tersebut biasanya harus diprioritaskan daripada pengambilan data.
Cara Memilih Opsi Terbaik
Pilih scraper AI-first ketika tata letak halaman berubah sering dan nilai bisnis membenarkan ulasan dan pemantauan. Pilih kerangka kerja crawler ketika tim dapat memelihara kode dan membutuhkan perilaku produksi yang dapat diulang. Pilih API pengambilan data yang dikelola ketika biaya infrastruktur adalah hambatan utama. Pilih otomatisasi browser ketika situs bergantung berat pada JavaScript atau interaksi mirip pengguna. Pilih CapSolver ketika alur kerja yang disetujui mencapai CAPTCHA atau tantangan validasi lalu lintas yang didukung dan tim membutuhkan jalur penyelesaian yang konsisten.
Tim keamanan dan kepatuhan sebaiknya terlibat sejak awal. Proyek Ancaman Otomatis OWASP menjelaskan pola otomatisasi yang tidak sah umum, yang membuatnya menjadi daftar periksa berguna untuk apa yang sistem bertanggung jawab harus hindari. Scraper yang bertanggung jawab harus mengenali dirinya ketika tepat, mematuhi batas, menghindari data sensitif, dan berhenti ketika izin atau perilaku halaman tidak jelas.
Kesimpulan
Alternatif scraper AI sebaiknya dievaluasi sebagai model operasional, bukan hanya alat. Tim terkuat menggabungkan API resmi, crawler deterministik, otomatisasi browser, ekstraksi AI, pemantauan, dan jalur pengecualian yang terdokumentasi untuk tantangan CAPTCHA. Jika alur kerja data web yang disetujui Anda membutuhkan penanganan tantangan yang andal sebagai bagian dari arsitektur tersebut, panduan pengambilan data web yang patuh dari CapSolver adalah referensi praktis karena menjelaskan bagaimana penyelesaian CAPTCHA sesuai dengan tata kelola otomatisasi yang bertanggung jawab.
FAQ
Apa itu alternatif scraper AI?
Alternatif scraper AI adalah alat atau arsitektur untuk ekstraksi data web, termasuk alat ekstraksi AI, otomatisasi browser, API pengambilan data, kerangka kerja crawler, dan sistem hibrid.
Kapan tim sebaiknya menggunakan otomatisasi browser untuk pengambilan data?
Gunakan otomatisasi browser ketika halaman target yang diizinkan memerlukan rendering JavaScript, interaksi mirip pengguna, atau ekstraksi data pasca-pemuatan yang tidak dapat ditangkap secara andal oleh permintaan HTTP sederhana.
Apakah setiap scraper AI memerlukan penyelesaian CAPTCHA?
Tidak. Penyelesaian CAPTCHA hanya relevan ketika alur kerja yang disetujui menghadapi tantangan yang didukung. Banyak tugas pengambilan data web sebaiknya menggunakan API resmi, ekstraksi statis, atau kemitraan data alih-alih CAPTCHA.
Bagaimana CapSolver dapat mendukung alternatif scraper AI?
CapSolver dapat mendukung alur kerja yang disetujui dengan menangani tantangan CAPTCHA dan validasi lalu lintas melalui jalur API yang terdokumentasi atau ekstensi browser, terutama dalam pengujian, pemantauan, dan otomatisasi browser.
Apa cara paling aman untuk memulai?
Mulailah dengan ulasan izin, ulasan robots.txt, dan pilot kecil. Kemudian bandingkan opsi API, crawler, browser, dan ekstraksi AI sebelum menambahkan penyelesaian tantangan CAPTCHA di tempat yang jelas dibenarkan.
Lihat Lebih Banyak
AutomationJul 07, 2026
Penanganan Captcha dalam Otomatisasi Pengajuan Persidangan Legaltech
Perbaiki penanganan captcha dalam otomatisasi pengajuan persidangan untuk LegalTech: alur kerja dan alat yang sesuai regulasi untuk mempermudah e-filing, mengurangi kesalahan, dan mempercepat pengajuan.
AutomationJul 07, 2026
Cara Menyelesaikan CAPTCHA dalam Sistem Pelacakan Inventaris E-commerce
Pelajari cara menyelesaikan captcha dalam pelacakan inventaris e-commerce dengan metode praktis, tips otomatisasi, dan kepatuhan untuk menjaga data stok tetap akurat dan skalabel.