How to Solve Imperva Incapsula When Web Scraping in 2024 | Complete Guide
How to Solve Imperva Incapsula When Web Scraping in 2024 | Complete Guide
Sora Fujimoto
AI Solutions Architect
29-May-2024
Web scraping has become an essential tool for gathering data from the internet, but with advancements in web security, solving protective measures has become increasingly challenging. One of the most formidable obstacles is Imperva Incapsula, a cloud-based application delivery service that includes robust web security, DDoS protection, CDN, and load balancing. This guide will provide you with a comprehensive understanding of Imperva Incapsula's security mechanisms and offer practical solutions for solving these measures while web scraping in 2024.
Table of Content
What is Imperva Incapsula
How to Determine if a Site is Protected by Imperva
The Challenge of Reverse Engineering
Network Connection Detection
How to Solve Imperva
How CapSolver Solves the Problem
Conclusion
1. What is Imperva Incapsula?
1.1 Introduction
Imperva Incapsula is a cloud-based application delivery service that includes web security, DDoS protection, CDN, and load balancing. It provides DDoS protection from layers 3/4 to layer 7 and DNS protection, as well as website acceleration. It detects bot activities, identifies their sources, and determines their nature. It allows useful bots (like Google crawlers) while blocking malicious or unwanted bots (like those used in cyberattacks).
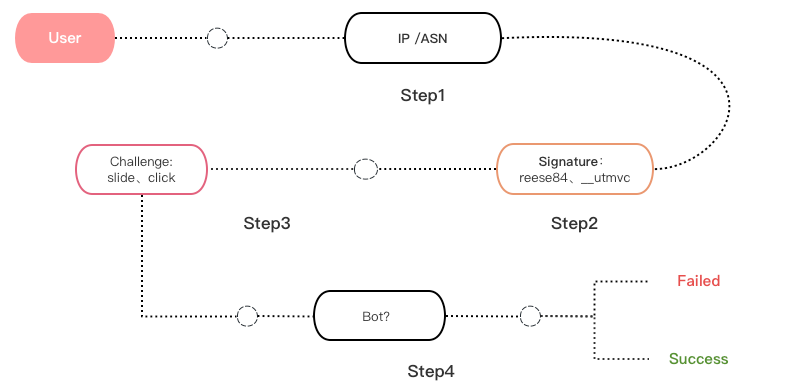
IP/ASN Reputation: Detects proxies and network request fingerprints.
Behavior Patterns: Monitors abnormal traffic and access frequency.
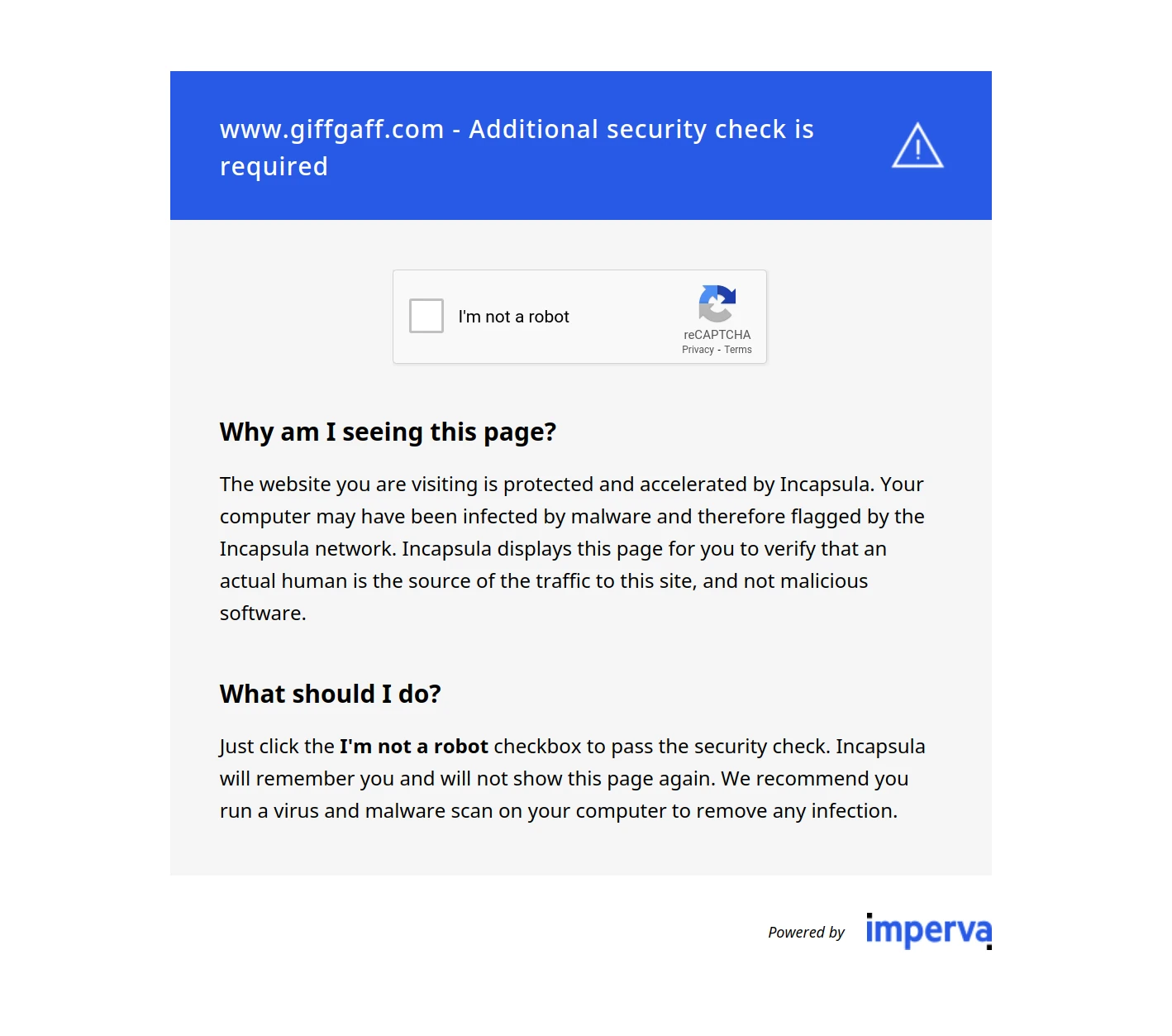
Tool/Bot Detection: Uses cookies, JavaScript, and third-party CAPTCHAs (like reCAPTCHA and GeeTest) for bot detection.
If you encounter a reCAPTCHA verification:
Access Restriction Determination Process:
When accessing an Imperva-protected website, a series of monitoring and tracking processes are conducted. If any step is deemed suspicious, a combination of checks is performed. The final score determines whether access is granted.
Struggling with the repeated failure to completely solve the irritating captcha?
Discover seamless automatic captcha solving with Capsolver AI-powered Auto Web Unblock technology!
Claim Your Bonus Code for top captcha solutions; CapSolver: WEBS. After redeeming it, you will get an extra 5% bonus after each recharge, Unlimited
2. How to Determine if a Site is Protected by Imperva
2.1 Checking Browser Requests
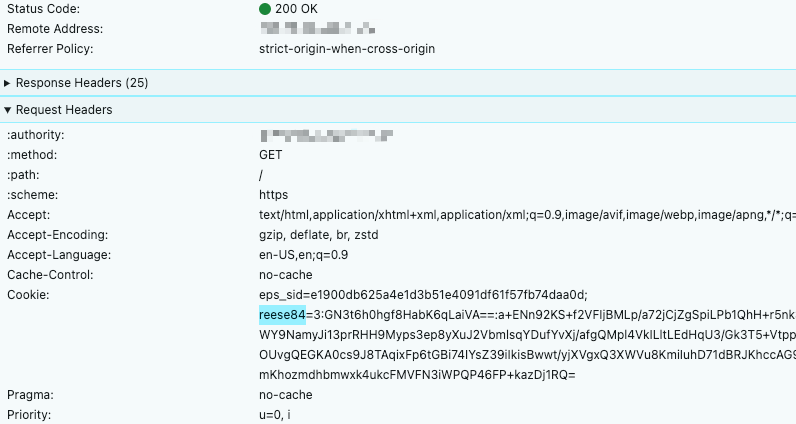
Usually, a failed access attempt returns a 4xx status code. Upon successful access after verification, the cookie will contain the reese84 parameter.
3. The Challenge of Reverse Engineering
The main parameters involved are __utmvc and reese84.
3.1 __utmvc Parameter
A related JS file executes and reconstructs a string into obfuscated code.
The code execution checks a variety of device-related fingerprint information:
Device hardware values: Bluetooth, sound, screen, etc.
OS and browser information: Window size, kernel version, OS version and type, etc.
Fingerprint information is encrypted using JavaScript.
3.2 reese84 Parameter
The generation of the reese84 token involves a large number of dynamic parameters.
reese84 includes dozens of fingerprints, and their number is constantly updated.
Each fingerprint has a > varying number of attribute keys. During collection, these keys are dynamic and obfuscated, making it hard to determine what fingerprint information is collected. The fingerprint calculation functions are also anonymous and dynamic, with around 20 such functions currently in use, and the number is growing.
Detecting whether the fingerprint information collected matches when accessed from different environments (Chrome, Safari, and browser version correlation)
The collected fingerprint information is encrypted and calculated, and the calculation process is obfuscated, making it unreadable.
4. Network Connection Detection
Information in the request header: language and IP address, browser version, and token parameters matching, etc.
IP proxy detection: Checks if the request comes from an ISP. Using residential proxies and mobile networks is usually allowed.
Access protocol: Most browsers now use HTTP2. Using HTTP 1.1 might be considered suspicious. For requests made with Python or Go, use libraries that support HTTP2.
TLS detection: Besides the HTTP version, the client-server connection is also checked. Requests made with Python or Go have noticeable differences in TLS compared to browser access. Modify TLS settings or use libraries that support TLS. Open-source projects offer such support.
Capsolver handles these network-related detections when generating usable cookies/tokens, making behavior more human-like to avoid bot detection.
5. How to Solve Imperva
Extremely high-quality IP proxies may grant direct access.
Browser automation tools like Puppeteer.
Node.js simulates browser environments to execute JS files and calculate parameters. Node.js can have memory issues, making it unsuitable for large-scale use.
CapSolver handles the complex parameter calculation processes, network environment (IP proxy/TLS fingerprint), and device fingerprint authenticity, making it more efficient than browser automation/Node.js methods and suitable for large-scale use.
Simply provide CapSolver with the URL and the corresponding reeseScriptUrl, and CapSolver will return a valid token to access the target website.
Obtaining reeseScriptUrl
After a failed access attempt, a JS file with a unique URL for each site is usually retrieved. Script URLs look like:
Imperva Incapsula calculates over 180 encrypted values based on collected fingerprints. Capsolver has solved these problems, you just need to call the API to get the solution and you can solve imperva directly, the python sample code is as follows:
import requests
import time
api_key = "YOUR_API_KEY"
website_url = "https://example.com/"
reese_script_url = "https://xxx.xxx.xxx.xxx/"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
proxy = 'http://127.0.0.1:7890'
def get_solution():
data = {
"clientKey": api_key,
"task": {
"type": 'AntiImpervaTaskProxyLess',
"websiteURL": website_url,
"userAgent": user_agent,
"reeseScriptUrl": reese_script_url,
"reese84": True,
}
}
uri = 'https://api.capsolver.com/createTask'
res = requests.post(uri, json=data)
print(res.text)
resp = res.json()
task_id = resp.get('taskId')
if not task_id:
print("failed to get taskId:", res.text)
return
while True:
time.sleep(1)
data = {
"clientKey": api_key,
"taskId": task_id
}
res = requests.post('https://api.capsolver.com/getTaskResult', json=data)
# print(res.text)
resp = res.json()
status = resp.get('status', '')
print('get status:', status)
if status == "ready":
print("successfully => ", res.text)
return resp.get('solution')
if status == "failed" or resp.get("errorId"):
print("failed! => ", res.text)
return
def request_site(solution):
headers = {
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'Accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'User-Agent': user_agent,
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en',
}
if solution.get('token'):
headers['cookie'] = solution.get('token')
headers['Accept-Language'] = solution.get('language')
res = requests.post(
website_url, headers=headers, proxies={"https": px}, timeout=(20, 20)
)
print(res.text)
print("response status code:", res.status_code)
if __name__ == '__main__':
solution = get_solution()
if solution:
request_site(solution)
Conclusion
Navigating the security measures imposed by Imperva Incapsula can be daunting, especially with its advanced bot detection techniques and complex fingerprinting mechanisms. However, with the right tools and understanding, it is possible to overcome these challenges effectively.
By leveraging solutions like CapSolver, which streamlines the process of handling complex parameter calculations and managing network environments, you can solve Imperva Incapsula's defenses more efficiently. CapSolver's ability to simulate human-like behavior through sophisticated token generation makes it particularly valuable for large-scale web scraping operations in 2024.
FAQ
To conclude this article, let's address some common questions about web scraping pages protected by Imperva:
Is it legal to scrape pages protected by Imperva?
Yes. Web scraping publicly accessible data is generally legal worldwide, provided that the scraping process does not harm the website.
Can cache services be used to solve Imperva?
Yes, public caching services such as Google Cache or Archive.org can occasionally be used to solve Imperva protection since these services are often whitelisted. However, not all pages are cached, and those that are may be outdated, making them less suitable for web scraping. Cached pages may also lack dynamically loaded content.
Is it possible to solve Imperva entirely and scrape the website directly?
While it is technically possible to solve Imperva's protection, doing so can be illegal in some jurisdictions and is generally not recommended due to the complexity and potential legal issues involved.
Compliance Disclaimer: The information provided on this blog is for informational purposes only. CapSolver is committed to compliance with all applicable laws and regulations. The use of the CapSolver network for illegal, fraudulent, or abusive activities is strictly prohibited and will be investigated. Our captcha-solving solutions enhance user experience while ensuring 100% compliance in helping solve captcha difficulties during public data crawling. We encourage responsible use of our services. For more information, please visit our Terms of Service and Privacy Policy.