












🤔 What is DataDome?
DataDome CAPTCHA is one of the tools that DataDome uses to differentiate between human users and bots. CAPTCHA, as mentioned before, stands for "Completely Automated Public Turing test to tell Computers and Humans Apart." It's a test designed to be easy for humans to pass but difficult for bots.
When DataDome's system detects suspicious activity that might suggest a bot, it can trigger a CAPTCHA challenge. The user must then successfully complete the CAPTCHA to prove they are human and not a bot.
A DataDome CAPTCHA challenge could look something like this representation:
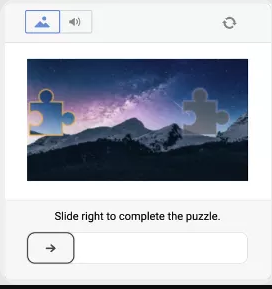
In this representation, the user is presented with a CAPTCHA image and a slider button that the user must complete the puzzle. Upon successfully completing the CAPTCHA, the user can proceed to access the website. If they fail or if the CAPTCHA isn't completed, the system may deny access or present another CAPTCHA challenge.
In summary, DataDome is a comprehensive bot protection solution that uses AI and machine learning to identify and block harmful bot activities. Its CAPTCHA challenge is one of the tools it uses to verify whether a user is a human or a bot, helping to maintain the security and integrity of the websites it protects.
In this blog, we will focus on solving Datadome Captcha.
How to identify DataDome
- There is a cookie called
datadome

- Datadome Captcha
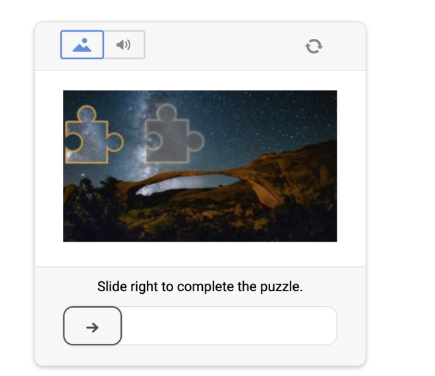
- Datadome Device check
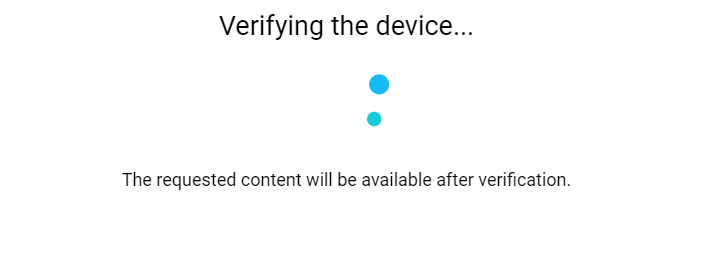
How to solve DataDome Captcha
👋 Before we start solving DataDome, there are some requeriments and points that we need to be aware that they are needed to know
🔒 Requeriments:
- Capsolver Key
- Proxy
🪄 Points to be aware that if you don't follow, solution will be invalid:
- The query parameters of the captcha url are obtained dynamic. This mean that you can't send a static captcha url over and over.
The query parameters are the bold words: https://geo.captcha-delivery.com/captcha/?initialCid=yourInitialCid&cid=yourCid&t=fe&referer=https%3A%2F%2Fantoinevastel.com%2Fbots%2Fdatadome&s=YourSParam&e=youreParam these are obtained in the first GET where you get the captcha - The query param t, need to have the value t=fe, if have t=bv, this mean the captchaUrl is banned and you can't submit us that.
- Match the proxy used for solve the captcha for interact with the page
- User Agent must be obtained from the documentation
Check the documentation to obtain the latest
Make sure that you understand all the points to make sure capsolver can solve the captcha correctly 🙄.
To solve datadome captcha you also need to understand our documentation: documentation.
If any parameter is missing, you will likely encounter issues with the token not being accepted by the website.
The first method that you need to use from the documentation is createTask, this method need the parameters of the picture.
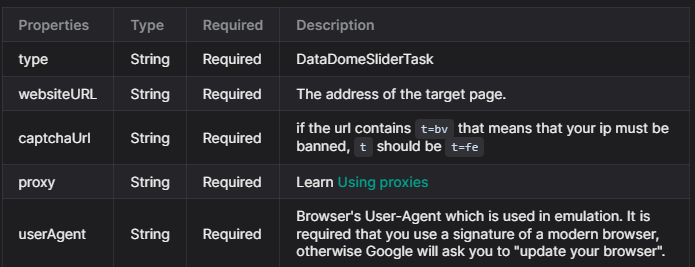
Some parameters are required and some are optional. Depends where you want to solve DataDome Captcha
For this example, we will only use the required parameters. The task types for datadome are:
DatadomeSliderTask: This task type requires your own proxies.
For this example, we will use DatadomeSliderTask as the site uses datadome captcha.
After read this basic guide to understand how you should do it, you are ready for solve datadome 🤩
Let's start! 🫣
☀️ Step 1: Submit the information to capsolver
Use the method createTask for submit the information:
POST https://api.capsolver.com/createTask
{
"clientKey": "Your_API_KEY",
"task": {
"type": "DatadomeSliderTask",
"websiteURL": "",
"captchaUrl": "",
"proxy": "yourproxy",
"userAgent": "check documentation for get user agent that you must use"
}
}🎯 Step 2: Get the results
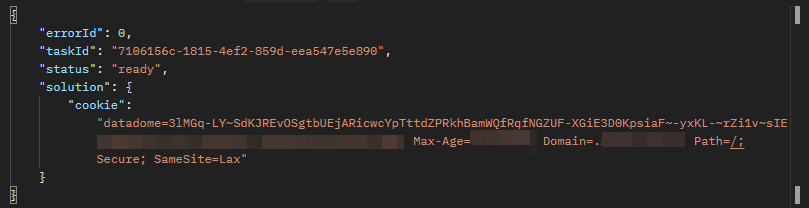
To verify the results, you'll need to continuously poll the getTaskResult API endpoint until the captcha is resolved.
Here's an example request:
POST https://api.capsolver.com/getTaskResult
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"YOUR_API_KEY",
"taskId": "TASKID_OF_CREATETASK" //ID created by the createTask method
}Once the captcha is successfully resolved, you'll receive a response similar to the one depicted in the following image:
How to solve DataDome Captcha and Interstinial with Python
# -*- coding: utf-8 -*-
import requests
import time
api_key = "API_KEY" # TODO: your api key
page_url = ""
proxy = "" # TODO: your proxy
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
def get_token(captcha_url):
print("call capsolver...")
data = {
"clientKey": api_key,
"task": {
"type": 'DatadomeSliderTask',
"websiteURL": page_url,
"captchaUrl": captcha_url,
"userAgent": user_agent,
"proxy": proxy,
},
}
uri = 'https://api.capsolver.com/createTask'
res = requests.post(uri, json=data)
resp = res.json()
task_id = resp.get('taskId')
if not task_id:
print("create task error:", res.text)
return
while True:
time.sleep(1)
data = {
"taskId": task_id
}
res = requests.post('https://api.capsolver.com/getTaskResult', json=data)
# print(res.text)
resp = res.json()
status = resp.get('status', '')
if status == "ready":
cookie = resp['solution']['cookie']
cookie = cookie.split(';')[0].split('=')[1]
print("successfully got cookie:", cookie)
return cookie
if status == "failed" or resp.get("errorId"):
print("failed to get cookie:", res.text)
return
print('solve datadome status:', status)
def format_proxy(px: str):
if '@' not in px:
sp = px.split(':')
if len(sp) == 4:
px = f'{sp[2]}:{sp[3]}@{sp[0]}:{sp[1]}'
return {"http": f"http://{px}", "https": f"http://{px}"}
def request_site(cookie):
headers = {
'content-type': 'application/json',
'user-agent': user_agent,
'accept': 'application/json, text/plain, */*',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': page_url,
'accept-encoding': 'gzip, deflate, br, zstd',
'accept-language': 'en-US,en;q=0.9,fr;q=0.8',
}
if cookie:
headers['cookie'] = "datadome=" + cookie
print("request url:", page_url)
response = requests.get(
page_url, headers=headers, proxies=format_proxy(proxy), allow_redirects=True
)
print("response status_code:", response.status_code)
if response.status_code == 403:
resp = response.json()
print("captcha url: ", resp['url'])
return resp['url']
else:
# print("response:", response.text)
print('cookie is good!')
return
def main():
url = request_site("")
if not url:
return
if 't=bv' in url:
print("blocked captcha url is not supported")
return
cookie = get_token(url)
if not cookie:
return
request_site(cookie)
if __name__ == '__main__':
main()The captcha token received can be verified by submitting the cookie datadome with the value of the response to the relevant site.
⚠️ **If the token is rejected, it may indicate that some information is missing or incorrect.
In conclusion, while solving datadome captcha may seem a daunting task, capsolver.com makes the process swift and efficient. By following the steps outlined above, you can easily resolve datadome.
Capsolver Team 💜





